Has anyone got a working example how to load a fastai model into pytorch, to use it for prediction?
I would like to be able to train my model in fastai, but then just load it with pytorch for prediction without having to install fastai.
Has anyone got a working example how to load a fastai model into pytorch, to use it for prediction?
I would like to be able to train my model in fastai, but then just load it with pytorch for prediction without having to install fastai.
Hi, I (we) are wondering the same thing! You can load the .h5 file by calling torch.load but we have no idea where to go from there.
I can’t believe this crucial step is so overlooked both in the notebooks and in this community.
I have been looking into this myself, I think you’ll find that this community is more focused on the perfection and R&D of the algorithms than the deployment.
If anyone has any tutorials on deploying these models that’d be great.
Hi, for images I got it to work quite easily.
Save your model with learn.save()
Then in a new file / notebook recreate your model architecture and create an instance of your model.
E.g. : m = Model()
Then do:
state = torch.load(‘path_to_saved_model.h5’)
m.load_state_dict(state)
And finally:
m.eval()
You can then predict by m(input).
Now, for the input, you ll need to preprocess it in the same way as the fast.ai library and to transform it to a Variable. It takes a bit of work but is totally doable.
Thanks for reply, I am trying to apply it to the model saved from “cats vs dogs” in lesson 1:
import torch
import torchvision.models as models
resnet34 = models.resnet34()
state = torch.load('224_all.h5')
resnet34.load_state_dict(state)
and it fails in load_state_dict with the error message:
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
488 elif strict:
489 raise KeyError('unexpected key "{}" in state_dict'
--> 490 .format(name))
491 if strict:
492 missing = set(own_state.keys()) - set(state_dict.keys())
KeyError: 'unexpected key "0.weight" in state_dict'
is it not the same kind of model? A different kind of resnet34 perhaps?
It looks the names for the keys in the state_dict get lost, after some digging I get this
RuntimeError: Error(s) in loading state_dict for ResNet:
Missing key(s) in state_dict: "conv1.weight", "bn1.weight", "bn1.bias", "bn1.running_mean", "bn1.running_var", "layer1.0.conv1.weight", "layer1.0.bn1.weight", "layer1.0.bn1.bias", "layer1.0.bn1.running_mean", "layer1.0.bn1.running_var", "layer1.0.conv2.weight", "layer1.0.bn2.weight", "layer1.0.bn2.bias", "layer1.0.bn2.running_mean", "layer1.0.bn2.running_var", "layer1.1.conv1.weight", "layer1.1.bn1.weight", "layer1.1.bn1.bias", "layer1.1.bn1.running_mean", "layer1.1.bn1.running_var", "layer1.1.conv2.weight", "layer1.1.bn2.weight", "layer1.1.bn2.bias", "layer1.1.bn2.running_mean", "layer1.1.bn2.running_var", "layer1.2.conv1.weight", "layer1.2.bn1.weight", "layer1.2.bn1.bias", "layer1.2.bn1.running_mean", "layer1.2.bn1.running_var", "layer1.2.conv2.weight", "layer1.2.bn2.weight", "layer1.2.bn2.bias", "layer1.2.bn2.running_mean", "layer1.2.bn2.running_var", "layer2.0.conv1.weight", "layer2.0.bn1.weight", "layer2.0.bn1.bias", "layer2.0.bn1.running_mean", "layer2.0.bn1.running_var", "layer2.0.conv2.weight", "layer2.0.bn2.weight", "layer2.0.bn2.bias", "layer2.0.bn2.running_mean", "layer2.0.bn2.running_var", "layer2.0.downsample.0.weight", "layer2.0.downsample.1.weight", "layer2.0.downsample.1.bias", "layer2.0.downsample.1.running_mean", "layer2.0.downsample.1.running_var", "layer2.1.conv1.weight", "layer2.1.bn1.weight", "layer2.1.bn1.bias", "layer2.1.bn1.running_mean", "layer2.1.bn1.running_var", "layer2.1.conv2.weight", "layer2.1.bn2.weight", "layer2.1.bn2.bias", "layer2.1.bn2...
Unexpected key(s) in state_dict: "0.weight", "1.weight", "1.bias", "1.running_mean", "1.running_var", "4.0.conv1.weight", "4.0.bn1.weight", "4.0.bn1.bias", "4.0.bn1.running_mean", "4.0.bn1.running_var", "4.0.conv2.weight", "4.0.bn2.weight", "4.0.bn2.bias", "4.0.bn2.running_mean", "4.0.bn2.running_var", "4.1.conv1.weight", "4.1.bn1.weight", "4.1.bn1.bias", "4.1.bn1.running_mean", "4.1.bn1.running_var", "4.1.conv2.weight", "4.1.bn2.weight", "4.1.bn2.bias", "4.1.bn2.running_mean", "4.1.bn2.running_var", "4.2.conv1.weight", "4.2.bn1.weight", "4.2.bn1.bias", "4.2.bn1.running_mean", "4.2.bn1.running_var", "4.2.conv2.weight", "4.2.bn2.weight", "4.2.bn2.bias", "4.2.bn2.running_mean", "4.2.bn2.running_var", "5.0.conv1.weight", "5.0.bn1.weight", "5.0.bn1.bias", "5.0.bn1.running_mean", "5.0.bn1.running_var", "5.0.conv2.weight", "5.0.bn2.weight", "5.0.bn2.bias", "5.0.bn2.running_mean", "5.0.bn2.running_var", "5.0.downsample.0.weight", "5.0.downsample.1.weight", "5.0.downsample.1.bias", "5.0.downsample.1.running_mean", "5.0.downsample.1.running_var", "5.1.conv1.weight", "5.1.bn1.weight", "5.1.bn1.bias", "5.1.bn1.running_mean", "5.1.bn1.running_var", "5.1.conv2.weight", "5.1.bn2.weight", "5.1.bn2.bias", "5.1.bn2.running_mean", "5.1.bn2.running_var", "5.2.conv1.weight", "5.2.bn1.weight", "5.2.bn1.bias", "5.2.bn1.running_mean", "5.2.bn1.running_var", "5.2.conv2.weight", "5.2.bn2.weight", "5.2.bn2.bias", "5.2.bn2.running_mean", "5.2.bn2.running_var", "5.3.conv1.weight", "5.3.bn1.weight", ...
Why might this be? Its literally the example from lesson1, so the resnet model has not been modified in any way. Any ideas?
If I dump
learn.models.model.state_dict()
in the lesson, before saving it, it also only got keys like “0.weight”
Hello @chloe2018, did you find any solution? Even I am facing same issuse.
sadly not, i still have the fastai dependency 
I made a new post yesterday, How to load fastai saved model with Pytorch-cpu. Also taged Mr Jeremy… His reply might ve useful. He didn’t reply yet.
The problem is, that the pyTorch version of the ResNet has the same backbone as the fastai version, but the head is different.
You could use the following code from the create_cnn method, to create the same net
a model created by
learn = create_cnn(data, models.resnet50, metrics=[accuracy])
learn.save('final_model')
can afterwards be loaded with
from fastai import *
from fastai.vision import *
import torch
loc = torch.load(base_path/'models/final_model.pth')
body = create_body(models.resnet50, True, None)
data_classes = 2
nf = callbacks.hooks.num_features_model(body) * 2
head = create_head(nf, data_classes, None, ps=0.5, bn_final=False)
model = nn.Sequential(body, head)
created the same network architecture as the one saved before
model.load_state_dict(loc['model'])
loads the saved weights from the initial model.
Hope this helps.
This helped me.
Thanks a lot.
Thank you very much!
I wasn’t noticed that learn.save on top saves ‘model’ and ‘opt’.
Hi @heye0507, can you let me know how you split off the ‘model’ and ‘opt’ sections from the .pth file? I’m inferring from your comment that you managed to do that somehow.
I’m stuck with the same issue, except I don’t really want to switch all the way to PyTorch. I’m just trying to load a .pth file into a text learner.
If I try to duplicate @mariopi’s method, but with what I think is a text model (AWD_LSTM):
body = create_body(models.AWD_LSTM, True, None)
I get an error:
TypeError: __init__() missing 3 required positional arguments: 'emb_sz', 'n_hid', and 'n_layers'
To be fair, I’m importing create_body from vision so that could be part of it. I’m not aware of the analogous text function.
Hi Rajan,
I don’t think create_body will work for text models (such as AWD_LSTM)
What you can do is create the learner, then do learn.model[0], It will grab the encoder out of the classification learner (before pooling).
For the model loading part, if you open the .pth file from fastai as a dict (I have to check how I load it to dict, but it is really simple), it will have obj['model] = {…your model weights}, obj[‘opt’] = {…you opt…}. You can model.load (check the Pytorch for exact method call) the obj[‘model’] part, or when you save fastai learner, set opt=False will get rid of opt.
I hope this helps 
Best,
Thanks Hao! I didn’t realize it would be that easy. I did this:
data = load_data(path, 'filename', bs=24)
learn1 = text_classifier_learner(data, AWD_LSTM, drop_mult=0.5)
learn1 = learn1.load('theModelIWantedToLoad')
At that point I could do a learn1.save_encoder to pick out the part I needed.
Thanks for the idea!
Hi mariopi,
how can predict using above code?
thanks
Hi,
I am not sure if I got your question.
You want to predict without using fastai?
Then you can just use the same examples as when predicting with a pytorch model.
To predict on the fastai learner you can just use learner.predict.
Therefore you will have to create the learner first. For example fastai v1
img = open_image(some_path)
learn = create_cnn(data, models.resnet50, metrics=[accuracy])
learn.model = model
learn.predict(img)
Hi,
with below code i loaded the model using torch and now i want to predict this model using torch not with fastai, that how can i do?
should i do model.predict(img)? or something else?
my code for ref.
import torch
import torchvision.models as models
from PIL import Image
loc = torch.load(‘path/model.pkl’,map_location=‘cpu’)
body = create_body(models.densenet161, True, None)
data_classes = 2
nf = callbacks.hooks.num_features_model(body) * 2
head = create_head(nf, data_classes, None, ps=0.5, bn_final=False)
model = nn.Sequential(body, head)
model.load_state_dict(loc)
Now i want to predict using this model with torch.
thanks
Just use
out = model(inp)
where, inp is the input as a tensor of the same shape as the input used for the model training (it should have the batch dimension as the first, say, n_b, then the number of channels, followed by height and width of the image, so, e.g., (1,3,224,224).
The output will be of shape (n_b, n_out), where n_out represents the number of output labels. Then you need to perform a torch.argmax(out, dim=1) to get the actual class label id.
I hope it helps.
Regards,
Sam
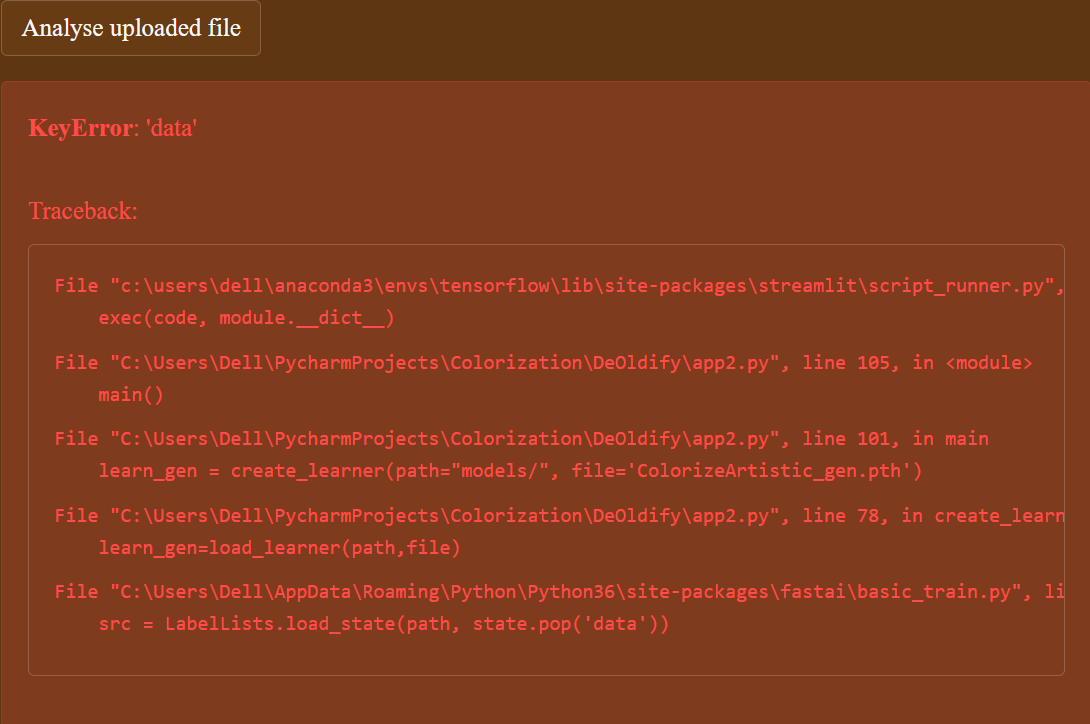
Hello Everyone,
I am receiving an error in loading fastai model. Anyone could help me out please?
In “app2.py” file receiving an error, please guide me what mistake I am making. I am stuck. Please Please!!!