I’d like to use this thread for questions about saving and loading databunches and models.
- I’ve seen both the use of
data.saveanddata.exportfor saving a newly createddatabunchusing the datablock API. What is the difference between the two and when to use which? - While working with text data for language model, I was able to run the following code for creation, save, and loading the text databunch:
Creation and save:
tok_proc = TokenizeProcessor(mark_fields=True)
num_proc = NumericalizeProcessor(max_vocab=60_091, min_freq=2)
data_lm = (TextList.from_df(texts_df, path, col=['name', 'item_description'], processor=[tok_proc, num_proc])
.random_split_by_pct(0.1)
.label_for_lm()
.databunch())
data_lm.save('lm-toknum')
Load:
tok_proc = TokenizeProcessor(mark_fields=True)
num_proc = NumericalizeProcessor(max_vocab=60_091, min_freq=2)
data_lm = TextLMDataBunch.load(path, 'lm-toknum', processor=[tok_proc, num_proc])
data_lm.show_batch()
What does data_lm.export() do in this context?
- Similar to above, I created a tabular
databunchusing the datablock API:
data_str = (TabularList.from_df(train_df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=[Categorify], test_df=test_df)
.split_from_df(col='is_valid')
.label_from_df(cols=dep_var, label_cls=FloatList, log=True)
.databunch(bs=128))
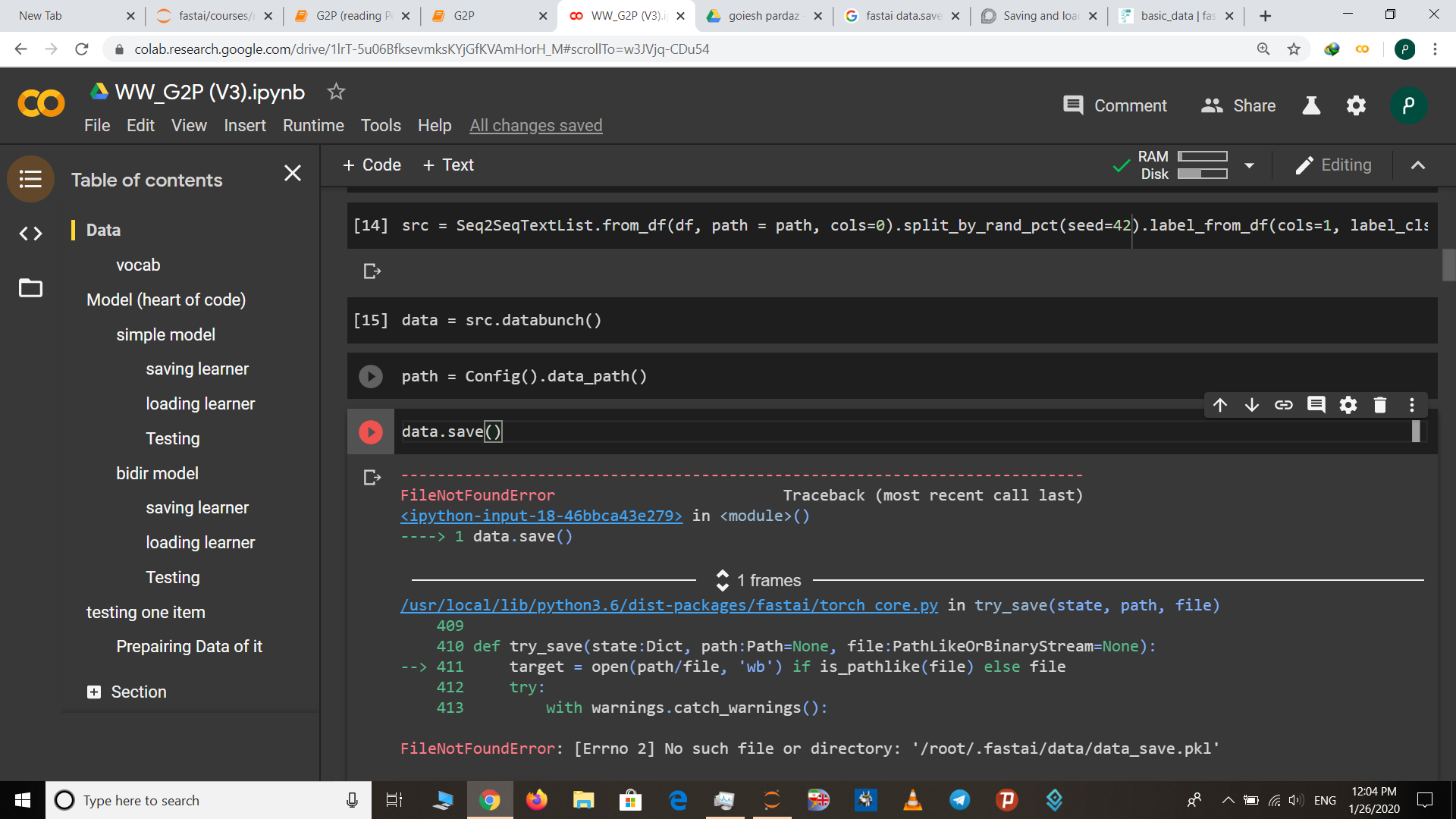
But when I tried to save it using data_str.save(), I got the following error:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-76-6facd85bdfbe> in <module>
----> 1 data_str.save('data-str')
~/fastai/fastai/basic_data.py in __getattr__(self, k)
118 return cls(*dls, path=path, device=device, tfms=tfms, collate_fn=collate_fn, no_check=no_check)
119
--> 120 def __getattr__(self,k:int)->Any: return getattr(self.train_dl, k)
121
122 def dl(self, ds_type:DatasetType=DatasetType.Valid)->DeviceDataLoader:
~/fastai/fastai/basic_data.py in __getattr__(self, k)
33
34 def __len__(self)->int: return len(self.dl)
---> 35 def __getattr__(self,k:str)->Any: return getattr(self.dl, k)
36
37 @property
~/fastai/fastai/basic_data.py in DataLoader___getattr__(dl, k)
18 torch.utils.data.DataLoader.__init__ = intercept_args
19
---> 20 def DataLoader___getattr__(dl, k:str)->Any: return getattr(dl.dataset, k)
21 DataLoader.__getattr__ = DataLoader___getattr__
22
~/fastai/fastai/data_block.py in __getattr__(self, k)
504 res = getattr(y, k, None)
505 if res is not None: return res
--> 506 raise AttributeError(k)
507
508 def __getitem__(self,idxs:Union[int,np.ndarray])->'LabelList':
AttributeError: save
How do I save this databunch?
- I was able to use the
exportmethod to save something (I’m not sure what was saved). But how do I load this saveddatabunchback into a variable later (similar to loading the text databunch showed earlier)?
Thanks.