I would like to save the trained model so I can use it in pytorch directly for inference (without being dependent on fastai).
Has anyone done this, and have some code snippets to share how to save it and load it in pytorch for prediction?
I would like to save the trained model so I can use it in pytorch directly for inference (without being dependent on fastai).
Has anyone done this, and have some code snippets to share how to save it and load it in pytorch for prediction?
There is a PyTorch tutorial for that. In fastai, the model is accessible from your Learner by typing learn.model, then you can use any PyTorch function you want.
Thanks, I run into some problems though:
I have saved my Resnet50 model from lesson1 like this:
torch.save(learn.model.state_dict(), "resnet50pytorch.pth")
and I am now trying to load it like this
import torch
from torchvision import models
model = models.resnet50(pretrained=True)
model.load_state_dict(torch.load("resnet50pytorch.pth"))
model.eval()
which gives me this error:
RuntimeError: Error(s) in loading state_dict for ResNet:
Missing key(s) in state_dict: "conv1.weight", "bn1.weight", "bn1.bias", "bn1.running_mean", "bn1.running_var", "layer1.0.conv1.weight", "layer1.0.bn1.weight", "layer1.0.bn1.bias", "layer1.0.bn1.running_mean", "layer1.0.bn1.running_var", "layer1.0.conv2.weight", "layer1.0.bn2.weight", "layer1.0.bn2.bias", "layer1.0.bn2.running_mean", "layer1.0.bn2.running_var", "layer1.0.conv3.weight", "layer1.0.bn3.weight", "layer1.0.bn3.bias", "layer1.0.bn3.running_mean", "layer1.0.bn3.running_var", "layer1.0.downsample.0.weight", "layer1.0.downsample.1.weight", "layer1.0.downsample.1.bias", "layer1.0.downsample.1.running_mean", "layer1.0.downsample.1.running_var", "layer1.1.conv1.weight", "layer1.1.bn1.weight", "layer1.1.bn1.bias", "layer1.1.bn1.running_mean", "layer1.1.bn1.running_var", "layer1.1.conv2.weight", "layer1.1.bn2.weight", "layer1.1.bn2.bias", "layer1.1.bn2.running_mean", "layer1.1.bn2.running_var", "layer1.1.conv3.weight", "layer1.1.bn3.weight", "layer1.1.bn3.bias", "layer1.1.bn3.running_mean", "layer1.1.bn3.running_var", "layer1.2.conv1.weight", "layer1.2.bn1.weight", "layer1.2.bn1.bias", "layer1.2.bn1.running_mean", "layer1.2.bn1.running_var", "layer1.2.conv2.weight", "layer1.2.bn2.weight", "layer1.2.bn2.bias", "layer1.2.bn2.running_mean", "layer1.2.bn2.running_var", "layer1.2.conv3.weight", "layer1.2.bn3.weight", "layer1.2.bn3.bias", "layer1.2.bn3.running_mean", "layer1.2.bn3.running_var", "layer2.0.conv1.weight", "layer2.0.bn1.weight", "layer2.0.bn1.bias", "layer2.0.bn1...
Unexpected key(s) in state_dict: "0.0.weight", "0.1.weight", "0.1.bias", "0.1.running_mean", "0.1.running_var", "0.1.num_batches_tracked", "0.4.0.conv1.weight", "0.4.0.bn1.weight", "0.4.0.bn1.bias", "0.4.0.bn1.running_mean", "0.4.0.bn1.running_var", "0.4.0.bn1.num_batches_tracked", "0.4.0.conv2.weight", "0.4.0.bn2.weight", "0.4.0.bn2.bias", "0.4.0.bn2.running_mean", "0.4.0.bn2.running_var", "0.4.0.bn2.num_batches_tracked", "0.4.0.conv3.weight", "0.4.0.bn3.weight", "0.4.0.bn3.bias", "0.4.0.bn3.running_mean", "0.4.0.bn3.running_var", "0.4.0.bn3.num_batches_tracked", "0.4.0.downsample.0.weight", "0.4.0.downsample.1.weight", "0.4.0.downsample.1.bias", "0.4.0.downsample.1.running_mean", "0.4.0.downsample.1.running_var", "0.4.0.downsample.1.num_batches_tracked", "0.4.1.conv1.weight", "0.4.1.bn1.weight", "0.4.1.bn1.bias", "0.4.1.bn1.running_mean", "0.4.1.bn1.running_var", "0.4.1.bn1.num_batches_tracked", "0.4.1.conv2.weight", "0.4.1.bn2.weight", "0.4.1.bn2.bias", "0.4.1.bn2.running_mean", "0.4.1.bn2.running_var", "0.4.1.bn2.num_batches_tracked", "0.4.1.conv3.weight", "0.4.1.bn3.weight", "0.4.1.bn3.bias", "0.4.1.bn3.running_mean", "0.4.1.bn3.running_var", "0.4.1.bn3.num_batches_tracked", "0.4.2.conv1.weight", "0.4.2.bn1.weight", "0.4.2.bn1.bias", "0.4.2.bn1.running_mean", "0.4.2.bn1.running_var", "0.4.2.bn1.num_batches_tracked", "0.4.2.conv2.weight", "0.4.2.bn2.weight", "0.4.2.bn2.bias", "0.4.2.bn2.running_mean", "0.4.2.bn2.running_var", "0.4.2.bn2.num_batches_tracked", "0.4.2.co...Yes, you’re not training a standard resnet50 in fastai, its head (with 1000 outputs) has been removed and replaced by a head suitable for your data. You’ll have to recreate the model to be able to load your file.
Note that this is why fastai exists: there are no function that do all of that directly for you in PyTorch. I’d suggest keeping fastai for the model creation, otherwise dig into the code to see the functions you’ll need and copy-paste them.
Ah yes, this issue. I’ve been dealing with it when I was trying pretrained weights from pytorch.
How I solved this was something like this:
model_dict = model.state_dict()
my_dict = torch.load('resnet50pytorch.pth')
my_dict.keys()
Find which one may look like `net_state_dict` or something similar,
my_dict = my_dict['the key']
my_dict = {k: v for k, v in my_dict.items() if k in model_dict}
model_dict.update(pre_dict)
model.load_state_dict(model_dict)
This was from pytorch to fast.ai but I believe it should work backwards as well
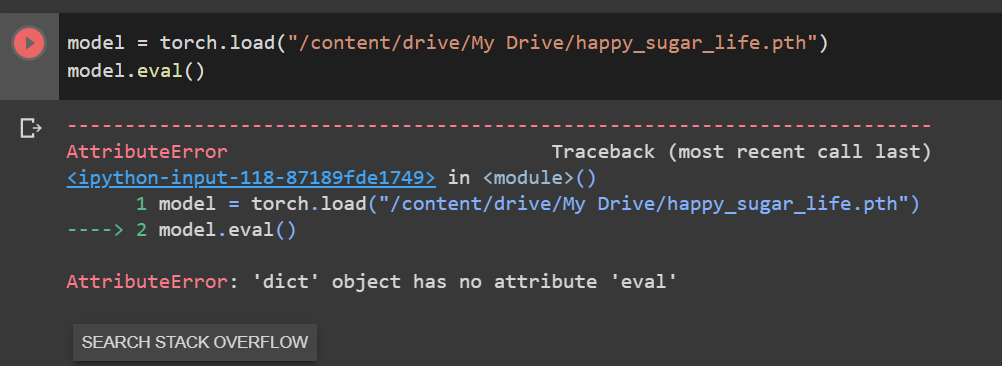
ok, so can I save the model that I created in Fastai, so I can load the same model in Pytorch;
E.g. somehow save the whole model architecture as well, and not just the weights and biases?
You can try to pickle the whole model, so torch.save(learn.model) then load it with model = torch.load(...). Not sure it will fully work.
According to the documentation that will probably bring me headaches when I put it on some other server:
The disadvantage of this approach is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved.
I will play around and see if I get somewhere, it would be great if one could export and use the model in production (just for inference) without installing the whole fastai.
Many thanks for your help!
This was stupid of me, of course pickling the whole model will still require to have the functions that create the model, so the fastai library.
I’m a bit surprised by the approach of “I want to use fastai to get their models but I don’t want it in production” but like I said, dig in the source code for the necessary functions to create your model. It should be mostly in vision.learner and maybe in layers and the core modules.
Hi, i got an error: pre_dict is not defined.
I was trying to load a pth file from fastai to pytorch.
This was meant to be a template, not an exact 
pre_dict represents the old model’s dictionary. Also, when you do your torch.load, you will most likely need to do:
torch.load()['model']
Hi, thank you for answering.
So…what should I put for the “pre_dict” in order to load a resnet34.pth from fastai(lesson1) to orginal pytorch’s torch.load?
I think a better example may be here: Loading pretrained weights that are not from ImageNet
What you should also do is on new_state_dict (when we assign it) also tag in the [‘model’] to the end.
Hi,it gives me this:
Shape mismatch at: 1.8.weight skipping
Shape mismatch at: 1.8.bias skipping
it won’t have any problem, right?
Take a look at what learn.model[1][8] is, would it make sense for it skip that layer? 
Thank You for helping. But my question is loading a pre-trained fastai lesson1 resent34.pth(exported from learner) to a pytorch model.
If it’s already exported just do torch.load(). This is what our load_learner does too. Now it’s just pytorch.
Hi, I just want to make sure. You are saying using torch.load() to load the pth or pkl file?
Both work the same. Doing a quick google search gave me: