Hi,
I have just recently prepared a custom image dataset in S3 and have taken the following steps:
- Separated the train and test images
- created a file called ‘train-annotations.csv’ & ‘test-annotations.csv’
- Uploaded images and notation files to S3. They are all at the same level in the folder:
e.g.

When I am in my Sagemaker notebook (conda_pytorch_p36), I am able to access the contents of the train-annotations.csv file but am struggling to access the images for my model.
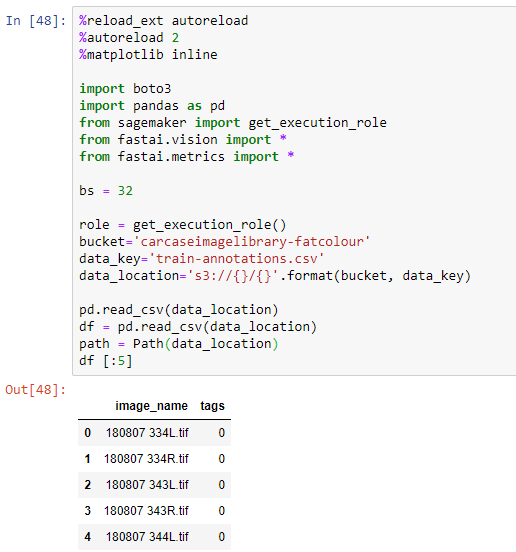
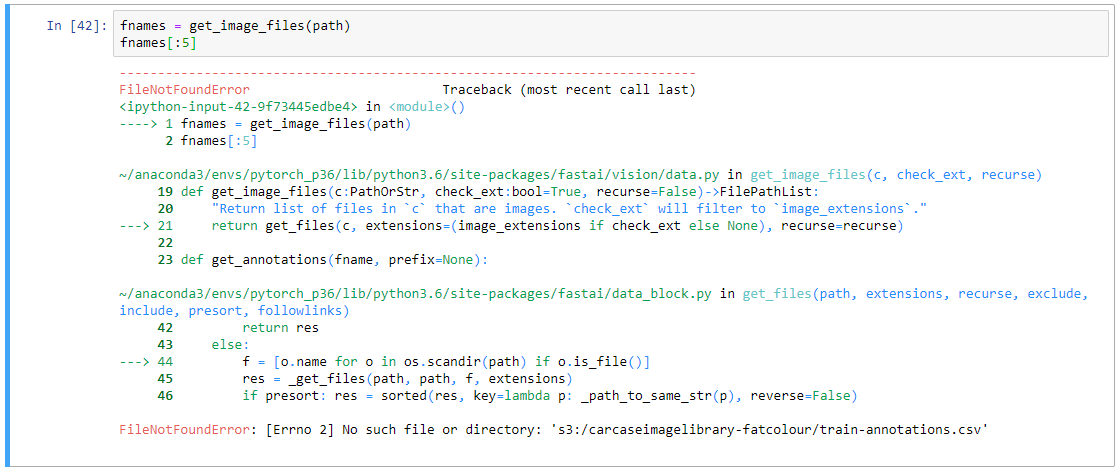
I would appreciate any advice as to how I can get this working, I took a similar approach recently with tabular data, but it was just a single csv file (i.e. not needing to handle 100’s of images). I am open to creating folder structures if needed. I am sure that this is due to my inexperience with the platform (just switched over from Colab/Google Drive to AWS Sagemaker/S3).
@matt.mcclean, would this be something you have come across?
Thanks
Andrew