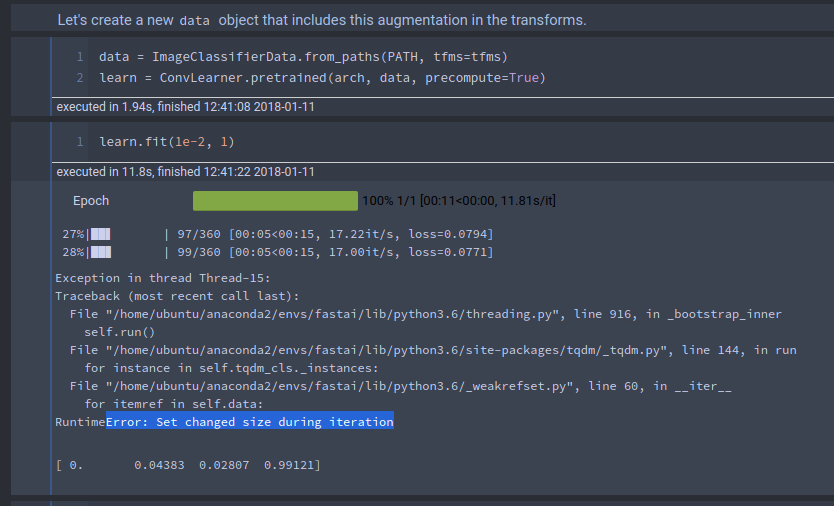
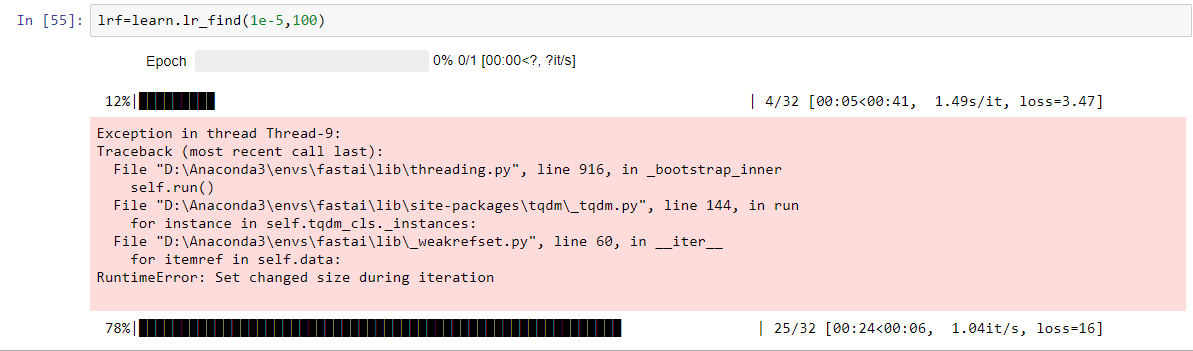
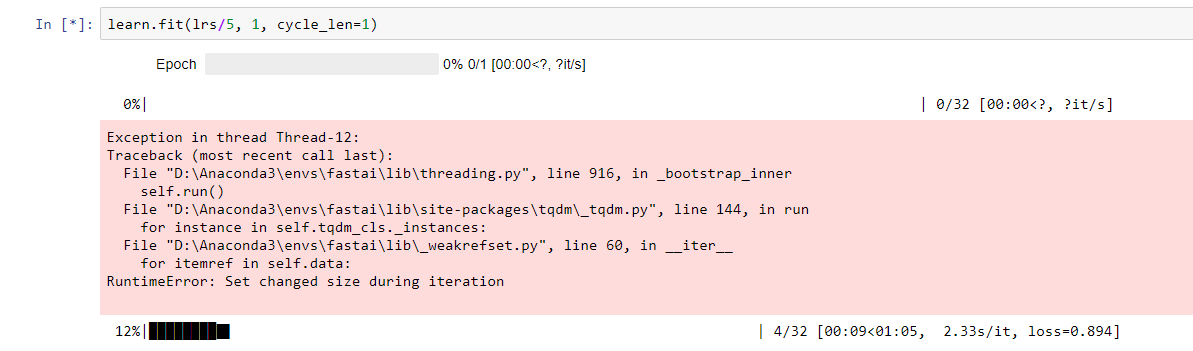
I’m occassionally getting this warning/error when I fit() or run lr_find() on my learner:
Exception in thread Thread-25:
Traceback (most recent call last):
File “/home/ubuntu/anaconda3/envs/fastai/lib/python3.6/threading.py”, line 916, in _bootstrap_inner
self.run()
File “/home/ubuntu/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_tqdm.py”, line 144, in run
for instance in self.tqdm_cls._instances:
File “/home/ubuntu/anaconda3/envs/fastai/lib/python3.6/_weakrefset.py”, line 60, in iter
for itemref in self.data:
RuntimeError: Set changed size during iteration
Regarding this error - I am also getting it in notebook 8. I think this is new behaviour and maybe something can be done to remove it?
I noticed that it was during the learning rate finder processing, maybe its because it does something to “interrupt an earlier command”, because I don’t remember doing anything…
I am also consistently hitting this issue in notebook 8, also on the line:
learn.fit(lrs/5, 1, cycle_len=1)
It always happens the very first time I run my notebook. I’m using the AWS fastai AMI on a p2.xlarge. I’ve ran git pull, conda env update, conda update --all and it hasn’t fixed the issue.
I thought there was an issue with my environment so I created a completely fresh AMI, re-downloaded all the data files, yet I’m still hitting this issue.
I can get the error to disappear after I run it a few times, however I’m worried this is not a complete solution because there can be unintended side-effects when running commands multiple times.
I have been experiencing and ignoring this error, as my LRs seem to work out correctly. But I’m guessing a deep dive into the code will find that at some point the code is not waiting on a global lock before updating the underlying set.
I got the same problem with personal setup (1080 ti). The problem is that if you ignore it and run again, it may run the remaining steps easily has to do it one by one. (I tried to run all to keep a record but stopped by this error.)
Seem you have to stop the kernel. Then run one or two steps and the try to run “all steps below”.