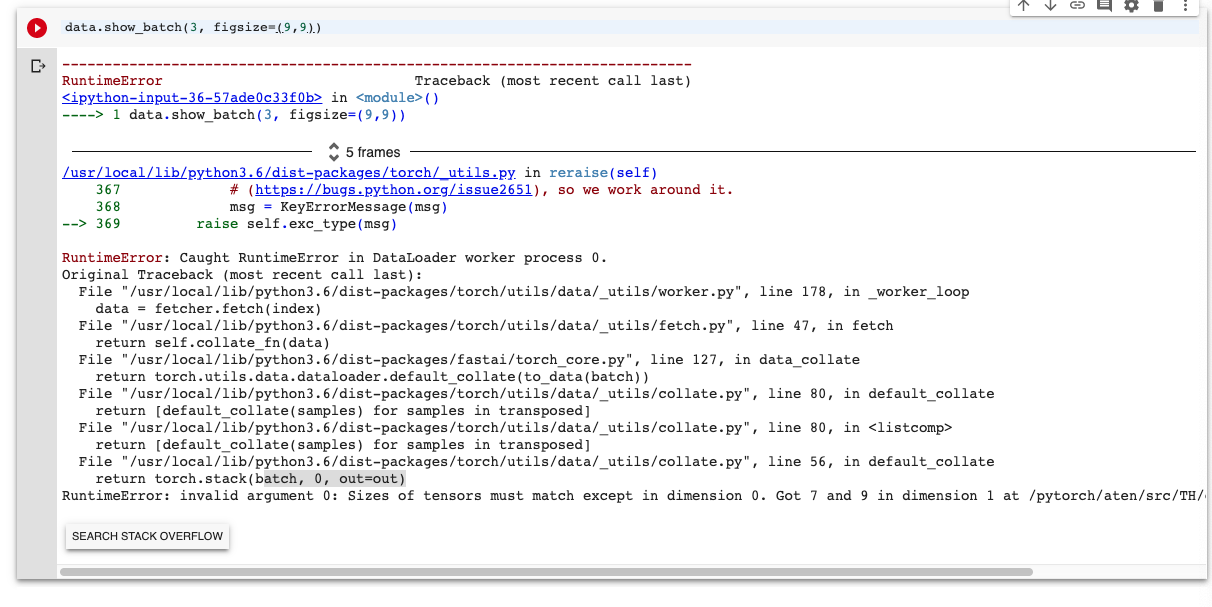
Tensors have to all be the same size. It looks like your get_points function is returning tensors of different sizes for different items (or at least for one item). According to the error one of them only has 7 points, not 9. So they can’t be combined into a single tensor for a batch. You’ll need to pad the data in such cases, with exactly what to pad with depending on the data. Or you could just drop such rows if there aren’t too many (especially if experimenting).
Items are loaded lazily so it won’t give an error until it encounters one. So you need to run fit in which case it should hit the error. Or you could just do for _ in progress_bar(data.train_ds): pass to run through all the items more quickly and (hopefully) trigger the error, pretty sure this should work.
Perhaps that’s not the issue, though given the error that looks like what it should be.
If you set num_workers=0 in the call to databunch then it won’t create a separate process for the worker. Then it might be easier to debug. You might have to try the python debugger. Check for a guide if you haven’t used it but based on that I’d run %debug in a new cell to open the debugger, run up 5 times to get to the _worker_loop function, then run print index which should hopefully display the indexes in your databunch of the batch causing problems. Run quit at the end to exit as you can’t run any other cells in Jupyter while it’s running (or just type q, all commands can be abbreviated like this and you can also run arbitrary python, though p <python> is safer as otherwise if your python starts with a command it will do the command).
Its bitter-sweet because. I dont know why setting batchsize to 1 work.
My hunch is that, tensors within a batch has to be same size. So by setting bs = 1, it allows tensors to be of different size because they are contained in a unique batch.
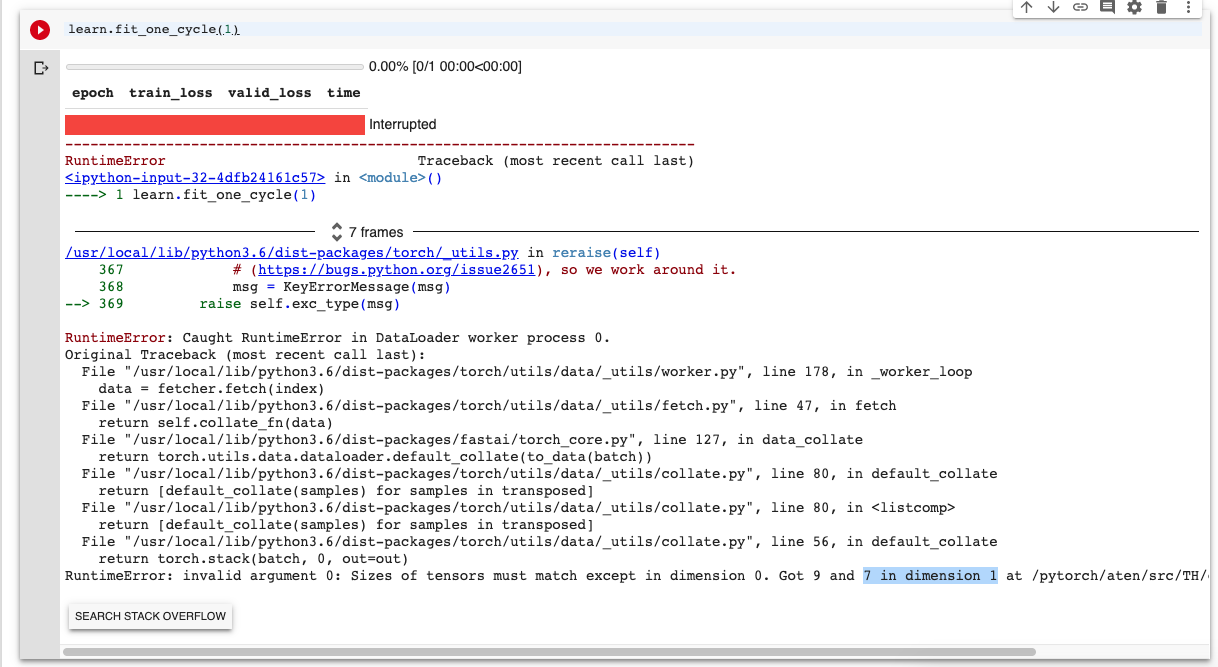
If you set batch size to 1 then every batch is only a single item, so it never has to collate items to make a single tensor. Thus it doesn’t matter if your items are different sizes.
However your training will be very slow as most of the performance advantages of using a GPU only happen with larger batch sizes.
The problem is the tensor size of my labels are different.
However, I checked the PointsLabelList in both valid and train for tensors that is not the size of torch.Size([9,2]). The count was 0. Meaning labels had the same tensor size.
But then when it create a databunch it show me I have some label thats that is not of torch.Size[9,2].
Yeah, it’s odd. As it’s happening in the dataloader collate it’s a little hard to debug as well.
If you set a low batch size, say 4 or 8, so it will hopefully trigger the error but your batches won’t be too big, then you could try using the python debugger to try and figure out exactly which item is causing the error.
This chapter looks like a good introduction to the python debugger if your not familiar with it.
Where the error occurs you’ll likely just have tensors not the original items/labels which won’t be very helpful. But if you go up the call stack a bit you should find at least the indexes of the items causing problems. Note that you can run something like src1.train.y[[0,5,9]] to see the labels for items 0, 5 and 9 (or replace y with x to see the items).
Yeah, as you’re creating the items from a folder you’d have to delete the image itself. Or once you find the item you might be able to figure out why it’s creating bad points and fix that. Or figure out what’s happening. Given you couldn’t replicate it by going through the items it might be something else. At least locating an item that causes issues should give you something to go on.
Good luck. Unfortunately you seem to have hit a pretty nasty error to track down. They aren’t all this bad and hopefully at least you’ll be better next time.
Okay, I have tracked part of the problem.
Thanks to debugger, I managed to push a little further.
I am seeing a very STRANGE behaviour. Let me explain.
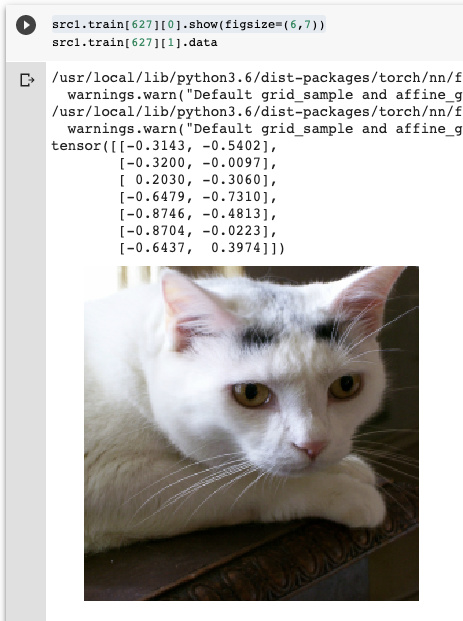
When I run the following to query about 1 specific image and its labels. I get
I then run it agian, on the same datapoint. The dimension and values of the labels completely change as well. Plus the image get transformed. I understand the values of the labels because the image get augmented/transformed. But the dimension changes as well, why?
That’s actually expected, mostly. And I think I figured out why you’re getting the error.
The transforms in fastai are random, so re-fetching the same item is giving you a new transform. As youe labels as image points fastai is also transforming your labels to match the transformed image.
So what might be happening with your error is that those transforms are not generating the correct number of points in some cases and that causes your error. That’s why you couldn’t trigger it by just iterating your data. I presume then you were iterating the list without transforms applied whereas here you have transforms applied (note that as you apply transforms to src1 rather than the databunch, as you should, and this happens in-place, once you call this src1 is now transformed, they’ve been added to it’s tfms collection).
You can try using .transform(..., tfm_y=False) (where … is whatever you passed before). That won’t actually work for learning here as now your labels won’t be correct when images are transformed, but you can try and fit an epoch without error to verify this is the issue. This can be useful though in other cases where transforms interfere with labels.
To resolve it you’ll either need to remove all transforms or find a set of transforms that doesn’t result in the error. I’d try setting max_warp=0. (I think) in get_transforms (assuming that’s what you’re using) as my first guess would be it’s the warp affine transforms causing the issue.
Or actually it may be crop as that might be cropping out some of the points and so dropping them. There might be some option to PointsItemList to resolve this. I haven’t actually used it.
I had a Eureka moment as I was writing my last post. Yes, get_transforms() seems to crop the image, so some time the ears of the cats would be cropped out. During this process, it also removes points from labels that related to this image. Hence, changing the size of the label tensor and the rest is history…Thus, I have decided to not apply any transformation
Finally, I have this
I will try playing around with max_wrap and see how that goes.
In hindsight, I learnt so much more about Fastai library during this process.
No problem, glad you finally got to the bottom of it
.
Actually, on further consideration, I think it’s more likely crop than warp. So then you’d want the max_zoom I think it is parameter (and maybe need a couple of others). Or you can just use a safer set of transforms. Simple flips without cropping or warping should be safe and still some augmentation.
I encountered the same problem when training CycleGan with images. Some of my images were not in the right size so make sure your images are all in the same size.