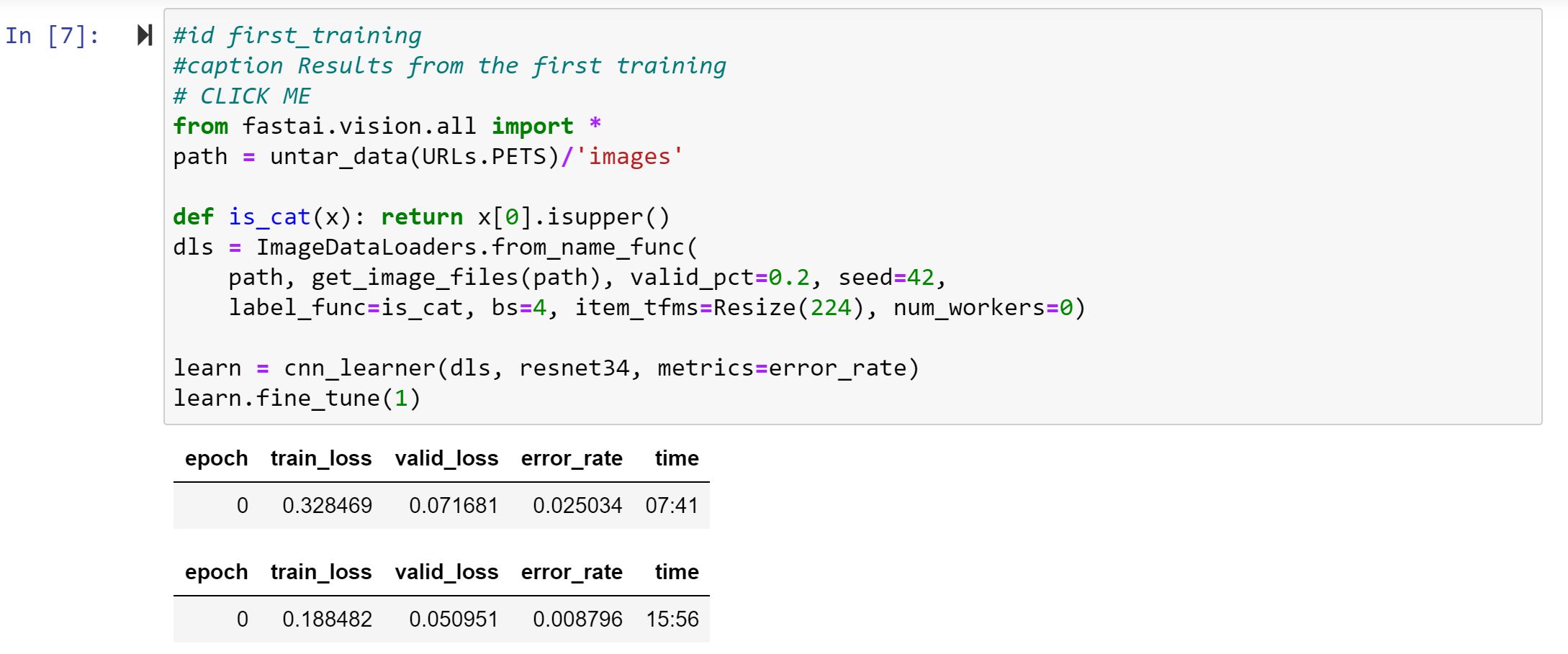
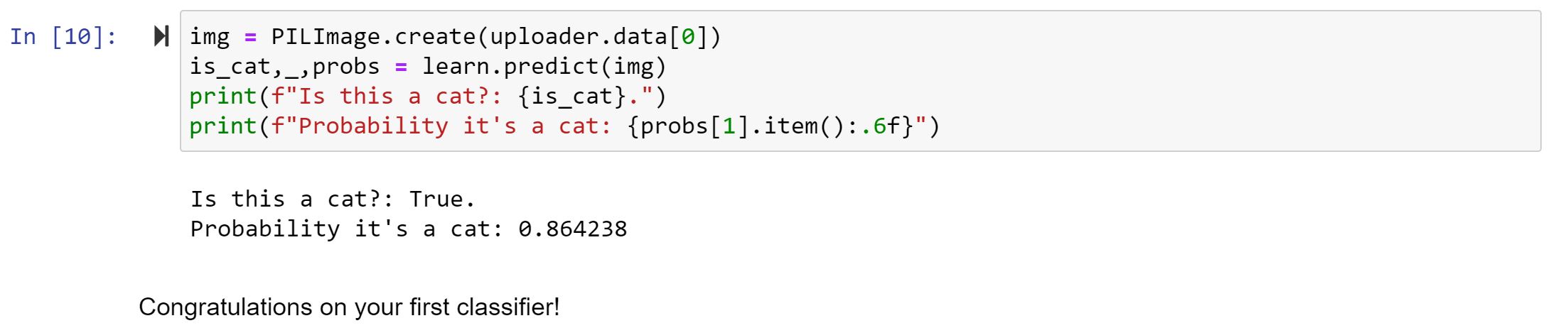
Hi all:
I’m trying to get the latest version of Fastai installed on my Windows 10 dev laptop (using miniconda) with a Nvidia 940M GPU and i7-6500U CPU and 12G RAM for the Jupyter Notebook latest version of the course. I keep running into runtime errors when I try to execute the code examples in the course from the GitHub course file I have downloaded locally. I’ve verified the 940M GPU is working properly using the CUDA devicequery. I’m using CUDA 11.
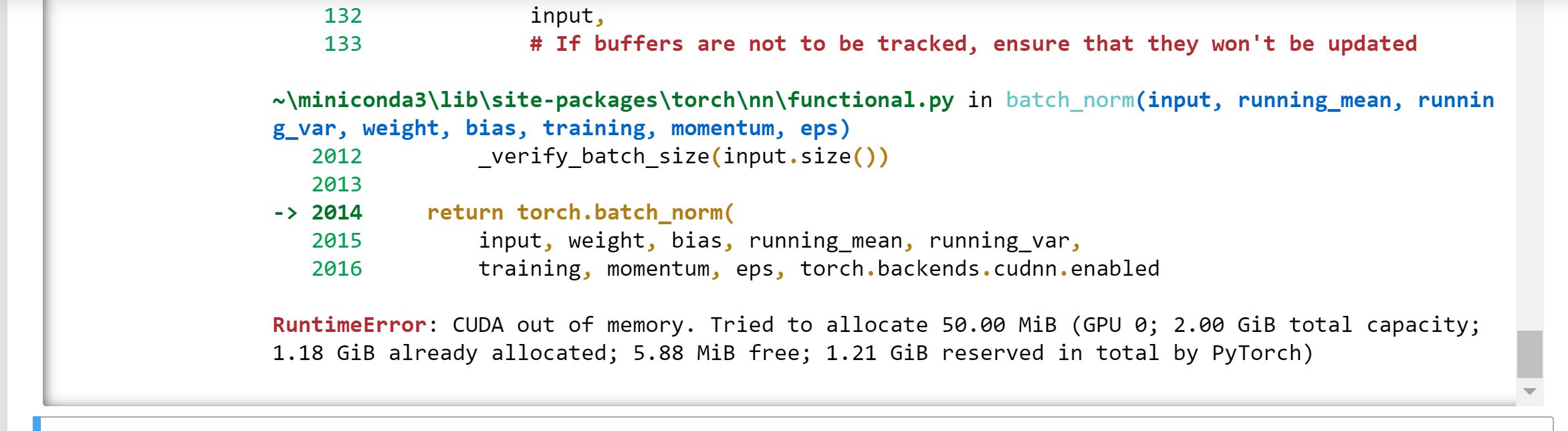
Here’s the error message from the first example from the Jupyter Notebook.
Note: I have a much more powerful Windows 10 workstation that I use for production activities. But I don’t want to install fastai on that system until I’m sure I can get fastai working on Windows 10 in a stable manner. So I’m wanted to get fastai stable and the install procedure for Windows 10 confirmed before attempting to install on the production Windows 10 workstation. I’ll look at the Linux CentOS 7 and CentOS 8 virtualized machine installs later on, I’m just specifically interested in the Windows 10 workstations and how fastai can work on those machines right now given they are our best machines.
epoch train_loss valid_loss error_rate time
0 nan 00:00
RuntimeError Traceback (most recent call last)
in
11
12 learn = cnn_learner(dls, resnet34, metrics=error_rate)
—> 13 learn.fine_tune(1)
~\miniconda3\lib\site-packages\fastcore\utils.py in _f(*args, **kwargs)
470 init_args.update(log)
471 setattr(inst, ‘init_args’, init_args)
→ 472 return inst if to_return else f(*args, **kwargs)
473 return _f
474
~\miniconda3\lib\site-packages\fastai\callback\schedule.py in fine_tune(self, epochs, base_lr, freeze_epochs, lr_mult, pct_start, div, **kwargs)
159 “Fine tune with freeze for freeze_epochs then with unfreeze from epochs using discriminative LR”
160 self.freeze()
→ 161 self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
162 base_lr /= 2
163 self.unfreeze()
~\miniconda3\lib\site-packages\fastcore\utils.py in _f(*args, **kwargs)
470 init_args.update(log)
471 setattr(inst, ‘init_args’, init_args)
→ 472 return inst if to_return else f(*args, **kwargs)
473 return _f
474
~\miniconda3\lib\site-packages\fastai\callback\schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
111 scheds = {‘lr’: combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
112 ‘mom’: combined_cos(pct_start, *(self.moms if moms is None else moms))}
→ 113 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
114
115 # Cell
~\miniconda3\lib\site-packages\fastcore\utils.py in _f(*args, **kwargs)
470 init_args.update(log)
471 setattr(inst, ‘init_args’, init_args)
→ 472 return inst if to_return else f(*args, **kwargs)
473 return _f
474
~\miniconda3\lib\site-packages\fastai\learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
205 self.opt.set_hypers(lr=self.lr if lr is None else lr)
206 self.n_epoch,self.loss = n_epoch,tensor(0.)
→ 207 self._with_events(self._do_fit, ‘fit’, CancelFitException, self._end_cleanup)
208
209 def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
~\miniconda3\lib\site-packages\fastai\learner.py in with_events(self, f, event_type, ex, final)
153
154 def with_events(self, f, event_type, ex, final=noop):
→ 155 try: self(f’before{event_type}') ;f()
156 except ex: self(f’after_cancel{event_type}‘)
157 finally: self(f’after_{event_type}’) ;final()
~\miniconda3\lib\site-packages\fastai\learner.py in _do_fit(self)
195 for epoch in range(self.n_epoch):
196 self.epoch=epoch
→ 197 self._with_events(self._do_epoch, ‘epoch’, CancelEpochException)
198
199 @log_args(but=‘cbs’)
~\miniconda3\lib\site-packages\fastai\learner.py in with_events(self, f, event_type, ex, final)
153
154 def with_events(self, f, event_type, ex, final=noop):
→ 155 try: self(f’before{event_type}') ;f()
156 except ex: self(f’after_cancel{event_type}‘)
157 finally: self(f’after_{event_type}’) ;final()
~\miniconda3\lib\site-packages\fastai\learner.py in _do_epoch(self)
189
190 def _do_epoch(self):
→ 191 self._do_epoch_train()
192 self._do_epoch_validate()
193
~\miniconda3\lib\site-packages\fastai\learner.py in _do_epoch_train(self)
181 def _do_epoch_train(self):
182 self.dl = self.dls.train
→ 183 self._with_events(self.all_batches, ‘train’, CancelTrainException)
184
185 def _do_epoch_validate(self, ds_idx=1, dl=None):
~\miniconda3\lib\site-packages\fastai\learner.py in with_events(self, f, event_type, ex, final)
153
154 def with_events(self, f, event_type, ex, final=noop):
→ 155 try: self(f’before{event_type}') ;f()
156 except ex: self(f’after_cancel{event_type}‘)
157 finally: self(f’after_{event_type}’) ;final()
~\miniconda3\lib\site-packages\fastai\learner.py in all_batches(self)
159 def all_batches(self):
160 self.n_iter = len(self.dl)
→ 161 for o in enumerate(self.dl): self.one_batch(*o)
162
163 def _do_one_batch(self):
~\miniconda3\lib\site-packages\fastai\data\load.py in iter(self)
101 self.randomize()
102 self.before_iter()
→ 103 for b in _loadersself.fake_l.num_workers==0:
104 if self.device is not None: b = to_device(b, self.device)
105 yield self.after_batch(b)
~\miniconda3\lib\site-packages\torch\utils\data\dataloader.py in init(self, loader)
735 # before it starts, and del tries to join but will get:
736 # AssertionError: can only join a started process.
→ 737 w.start()
738 self._index_queues.append(index_queue)
739 self._workers.append(w)
~\miniconda3\lib\multiprocessing\process.py in start(self)
119 ‘daemonic processes are not allowed to have children’
120 _cleanup()
→ 121 self._popen = self._Popen(self)
122 self._sentinel = self._popen.sentinel
123 # Avoid a refcycle if the target function holds an indirect
~\miniconda3\lib\multiprocessing\context.py in _Popen(process_obj)
222 @staticmethod
223 def _Popen(process_obj):
→ 224 return _default_context.get_context().Process._Popen(process_obj)
225
226 class DefaultContext(BaseContext):
~\miniconda3\lib\multiprocessing\context.py in _Popen(process_obj)
325 def _Popen(process_obj):
326 from .popen_spawn_win32 import Popen
→ 327 return Popen(process_obj)
328
329 class SpawnContext(BaseContext):
~\miniconda3\lib\multiprocessing\popen_spawn_win32.py in init(self, process_obj)
91 try:
92 reduction.dump(prep_data, to_child)
—> 93 reduction.dump(process_obj, to_child)
94 finally:
95 set_spawning_popen(None)
~\miniconda3\lib\multiprocessing\reduction.py in dump(obj, file, protocol)
58 def dump(obj, file, protocol=None):
59 ‘’‘Replacement for pickle.dump() using ForkingPickler.’‘’
—> 60 ForkingPickler(file, protocol).dump(obj)
61
62 #
~\miniconda3\lib\site-packages\torch\multiprocessing\reductions.py in reduce_tensor(tensor)
238 ref_counter_offset,
239 event_handle,
→ 240 event_sync_required) = storage.share_cuda()
241 tensor_offset = tensor.storage_offset()
242 shared_cache[handle] = StorageWeakRef(storage)
RuntimeError: cuda runtime error (801) : operation not supported at …\torch/csrc/generic/StorageSharing.cpp:247
These runtime errors are most likely related to how fastai is installed on this Windows 10 system. I have read several different versions of how to install fastai on Windows 10 using miniconda and they vary a great deal.
All the other runtime fix suggestions about this CUDA runtime 801 runtime error associated with the “dataloader” function having to be set to “0”, I don’t get what people are saying.
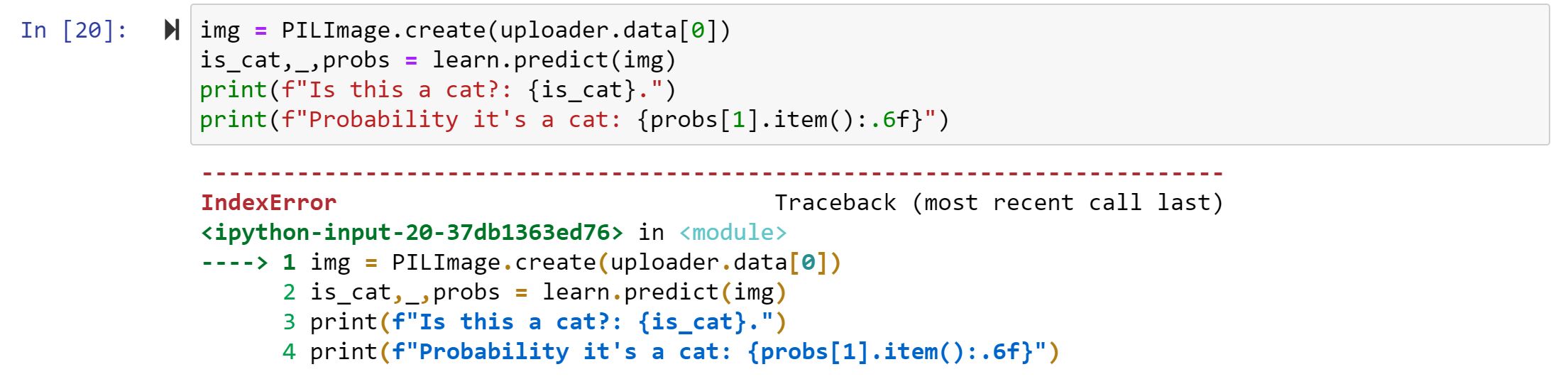
This is not the only runtime error. But I figure I’d start with this first bit of code from the course, I can’t get to execute.
Thanks for your help and time.