I ran the code in the first notebook of the course(breeds) on my RTX2080. For the initial Resnet model, each epoch took around 1:50 - 2:00 and it took a while to even start training. My task manager showed that there was less than 3% GPU utilization and 100% CPU utilization every time the progress bar moved. The whole model took around 6 mins to train. Is this the normal training time or is my system not using my GPU.
I am running Windows 10 and all my drivers are updated. Pytorch also recognizes my GPU.
I think it’s just a misuse of the task manager. Try to click on Video Encode. You’ll see a menu where you can chose which “functionnality” to monitor. You must select “cuda” to see if your gpu is used by pytorch
Well, CUDA shows utilisation. That’s good. There seems to be a long ‘idle’ time between epochs, when there is no cpu or GPU utilisation. Is this normal?
I’m not an expert in this topic, but as far as I know there are a lot of transformations going on (resize + image augmentation) which presumably is done on CPU. So in your case CPU becomes bottleneck.
You can check it by preparing your images (convert it to one of the desired sizes) and turning off augmentation (GPU utilisation should increase significantly).
Also you can check this tutorial section on how to use improve image processing performance
I dual-booted into Linux on the same machine and the new results are as different as night and day. Not only the model training but even the rest of the functions are amazingly fast.
I did not do anything. Just ran the code as is. I tested it again on a fresh Ubuntu install(18.04) and I got the same results. All the models are leagues faster than in Windows.
I installed conda, used it to install Pytorch with cuda 10.1(not 10.0). Then used pip to install fastai as conda threw up errors when I tried to use it. I did not install CUDA or cudnn individually as pytorch installed them for me.
I’m on Win10 and I find that I have to set numworkers=0 or else it blows up with a pickle fork error.
It’s possible then your num workers is 0 (if fastai realizes the same) and thus your bottleneck is the CPU, as you only have one thread to do the augmentations before handing to the GPU.
I think one of the notebooks has a way to push augmentations to the GPU instead of CPU (course 2, maybe notebook 9 or 10 or so).
Anyway, unless that pickle fork error has been fixed, you are forced to use only one thread for CPU augmentations vs on linux, you normally run 12 or so Thus, it might be 12x+ faster on Linux vs Windows. It takes me about 5 mins per epoch on Windows vs about 20sh seconds per epoch on Linux.
@abhishikthsagar, did you ever figure out what was going on? I just tried training on an RTX 2070 and am having the same problem (slow training times, ~ 1:30-2 minutes per epoch).
Thanks for the response. I forgot to mention I was already dual booted into linux; I connected to a power source on my laptop and that halved my training time to ~45s per epoch . I guess I would have expected it to be a little faster than that (even after increasing batch sizes) for the RTX 2070.
Hi…Nvidia released those percentages/benchmarks in their non-definitive proof kind of way, but we can presume that would be with Real-Time Ray Tracing and Deep Learning Super Sampling enabled.
I wasn’t talking about the general performance(which would be affected by DLSS and Ray tracing in games). I was basing it on the number of CUDA cores( which 2080 has 640 more than 2070) and clock speeds. @bibsian’s 2070 was taking nearly thrice as long as my 2080. I just assumed that the difference wouldn’t be so big.
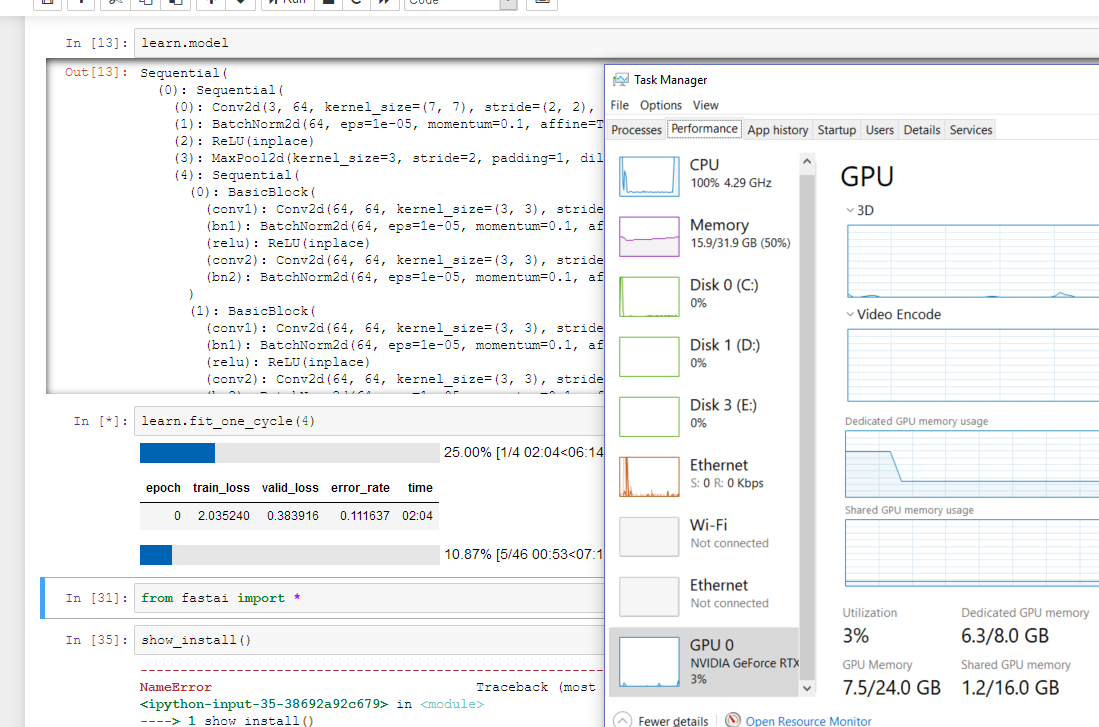
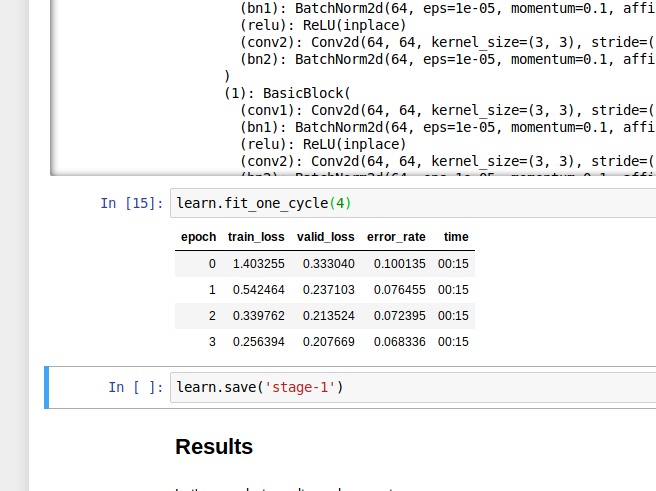
 Thus, it might be 12x+ faster on Linux vs Windows. It takes me about 5 mins per epoch on Windows vs about 20sh seconds per epoch on Linux.
Thus, it might be 12x+ faster on Linux vs Windows. It takes me about 5 mins per epoch on Windows vs about 20sh seconds per epoch on Linux.