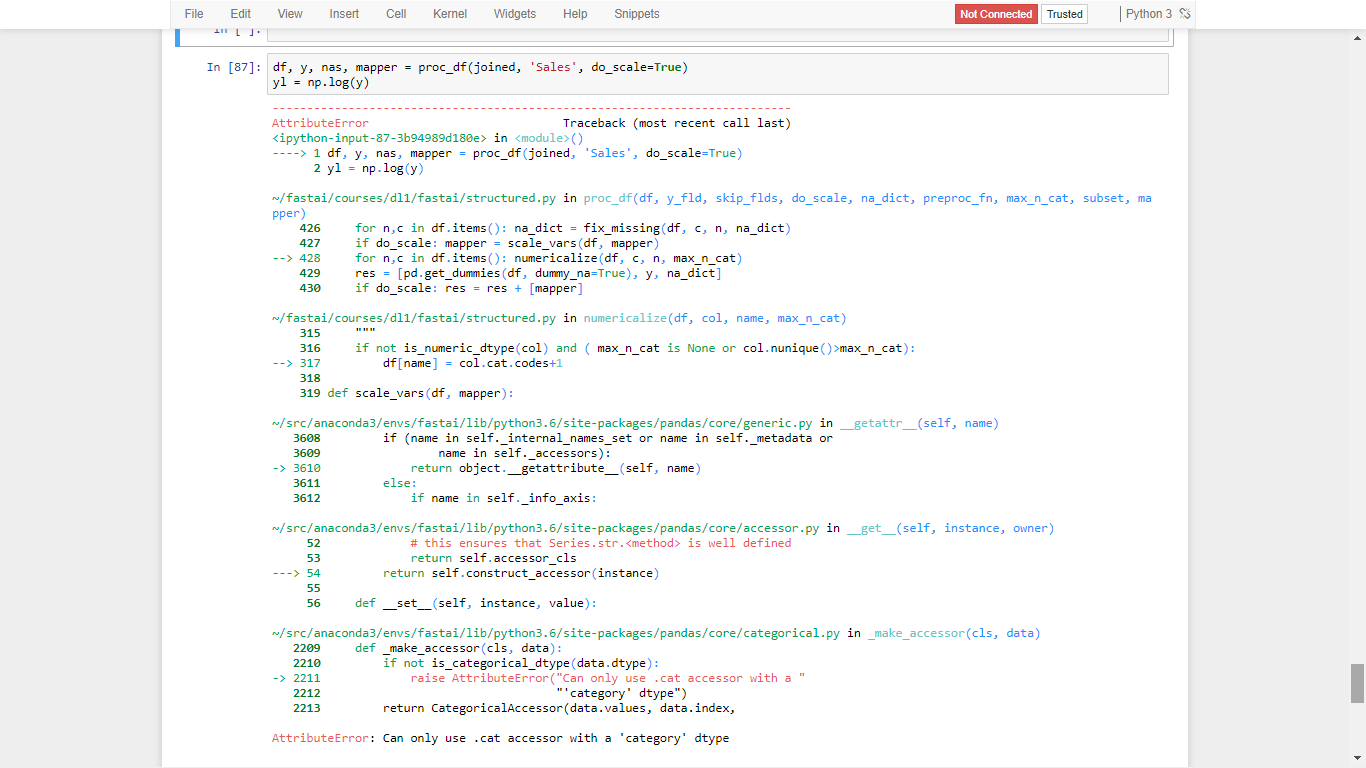
Note: I’ve not made any changes to lesson 3 notebook yet I face this issue. I even tried restarting Kernel and executing all code lines again to see I could avoid NaN but it didn’t work.
What @arjunrajkumar suggests worked for me fine without any errors.
I changed the second df to df_test and kinda duplicated nearly everything afterwards, until we merge back these dataframes into joined and joined_test later in the notebook.
This is because you probably did not convert joined’s cat_var’s to type ‘category’.
Sending from mobile(so cant check the code), but Jeremy had written a for loop where you go thru each and convert.
Note that in general I don’t design the notebooks to be just run top to bottom (although the 1st lessons are OK to do that). Be sure to think about what every line is doing, and when/whether to use it. Here’s some more details http://wiki.fast.ai/index.php/How_to_use_the_Provided_Notebooks