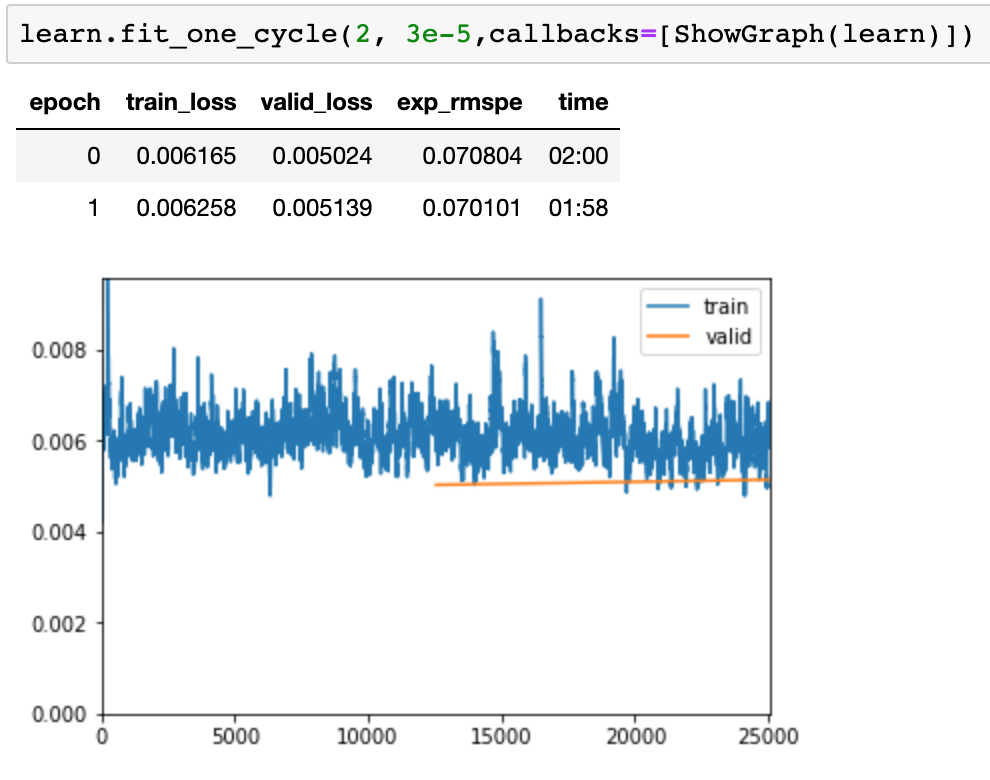
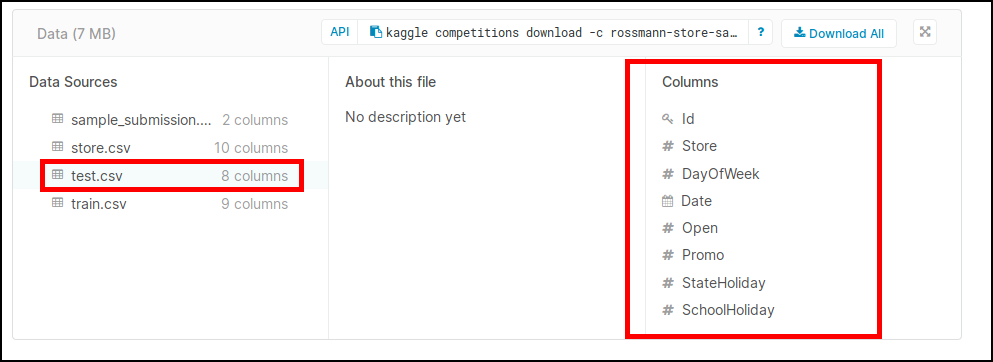
I was learns details of Rossmann examples. Here all columns are either categorical or continuous except dependent variable. But ‘Customer’ column is neither of them? Is there a specific reason or am i missed out something?
Another question, can we have multiple dependent variables, examples ‘sales’ and let us say ‘StoreType’ ?
I am not sure what values there are in the ‘Customer’ column? Is this some sort of id? If it is, then we probably don’t want to use it for training.
With deep learning having multiple losses is really simple, so yes, you can train both with sales and StoreType as your target and you can mix all sort of loss functions (as in, you can use the nll loss and sum it with rmse, each taking in different parts of the outputs of your model - this is nicely explained in part 2 of the course).
I am not quite sure, but let say its actual an ID. Than we also have Store_ID in the table too and that is marked as categorical. Another point, let us say we want to predict how many customers visit the same store often Vs others stores. My point is if i want to use customer field as one of the feature for my system to learn.
You might want to. If you feel that there are some commonalities between customers that can be inferred or some individual characteristics to be learned. I am not sure there is a hard rule - you probably need a bit of data on each customer (multiple entries) and then it is a question of experimenting if you can make this information useful / if there indeed is any information to be learned here.
Thanks @radek
So this essentially means, that each customer ID should have multiple entries to calculate loss for customer column. Am i correct? If this statement is right, then (in general) the columns which we want system to learn should always have multiple entries for that ID.
I have another stupid question: What if all my columns in the table are categorial variables and no single continuous variables. Because during the class following question was asked:
Question: Are embeddings suitable for certain types of variables? [01:02:45]
Jeremy’s Answer: Embedding is suitable for any categorical variables. The only thing it cannot work well for would be something with too high cardinality. If you had 600,000 rows and a variable had 600,000 levels, that is just not a useful categorical variable. But in general, the third winner in this competition really decided that everything that was not too high cardinality, they put them all as categorical. The good rule of thumb is if you can make a categorical variable, you may as well because that way it can learn this rich distributed representation; where else if you leave it as continuous, the most it can do is to try and find a single functional form that fits it well.
So does this mean continuous variables are essentials to fit the data?
As a rule of thumb, the less date you have per customer, the less your model will be able to infer about them. With little data per customer you might want to try smaller embedding dimensionality, but at some point even this might not be helpful. But then again in the original paper quite amazing things are achieved with very little data so it is best to try and see what results you can achieve.
In rossmann example, we were predicting ‘sales’, so we make it dependent variable. But otherwise, if we look at the data type of ‘sales’ it is continuous variable in nature. Now, if we look at train.csv table we have ‘sales’ against each entry in the table and we are fine.
Now, assuming we are predicting store_type having maximum visitor traction. Whereas store_type data type is categorical in nature. So it becomes important to have multiple entries for all the discrete categories in the store_type. Hence i feel when we pick dependent variable, we must also look at the actual data-type of the dependent variable and based on that dataset should have enough entries for each specific category.
I noticed most people don’t even mention that "Customers" column. If you put it neither as categorical or continuous in the Datablock API my guess is that fastai just ignores it. Furthermore, if you add it, it will fail, since that column is only present on the train set, not on the test set.
My hypothesis is that this is literally the amount of customers buying stuff, so a continuous variable. Each customers can buy several items, hence the Sales are higher than the Customers (Typically this is ~10x which seems not that far off, may a bit too high). It also makes sense not to have it on the Test set, since we want to predict the Sales, and normally you don’t have the number of customers you will have.
What I did was to follow the lesson as normal, but to first predict the “Customers” column of the test set. I get:
I believe it is the number of customers for that date/shop.
It is a data that does not exist in the test set, therefore you won’t be able to use it on your model and should be removed. Similar things happen in other competitions.
It is not mentioned here, but ‘Date’ is also not in categorical/continuous.
I believe it is left on the df just for calculations (like when we calculate the idx for the validation set), but you don’t want to pass it to the NN (as its info has been decomposed already).