I started conducting a very preliminary work similar to this useful paper. In most active learning frameworks we try to come up with an uncertainty measure - there are many different algorithms you can use for this here is a good survey paper.
Once uncertainties are measured then user can decide whether to annotate, psuedo-label or ignore unlabeled samples. But there is one important caveat:
- Is uncertainty measure and prediction performance correlated? (In a perfect scenario we would see a correlation of -1)
For testing this hypothesis I trained a binary segmentation model for few epochs and used entropy based uncertainty.
Train 15 epochs (1.5k) - Plotting samples out of training (5k)
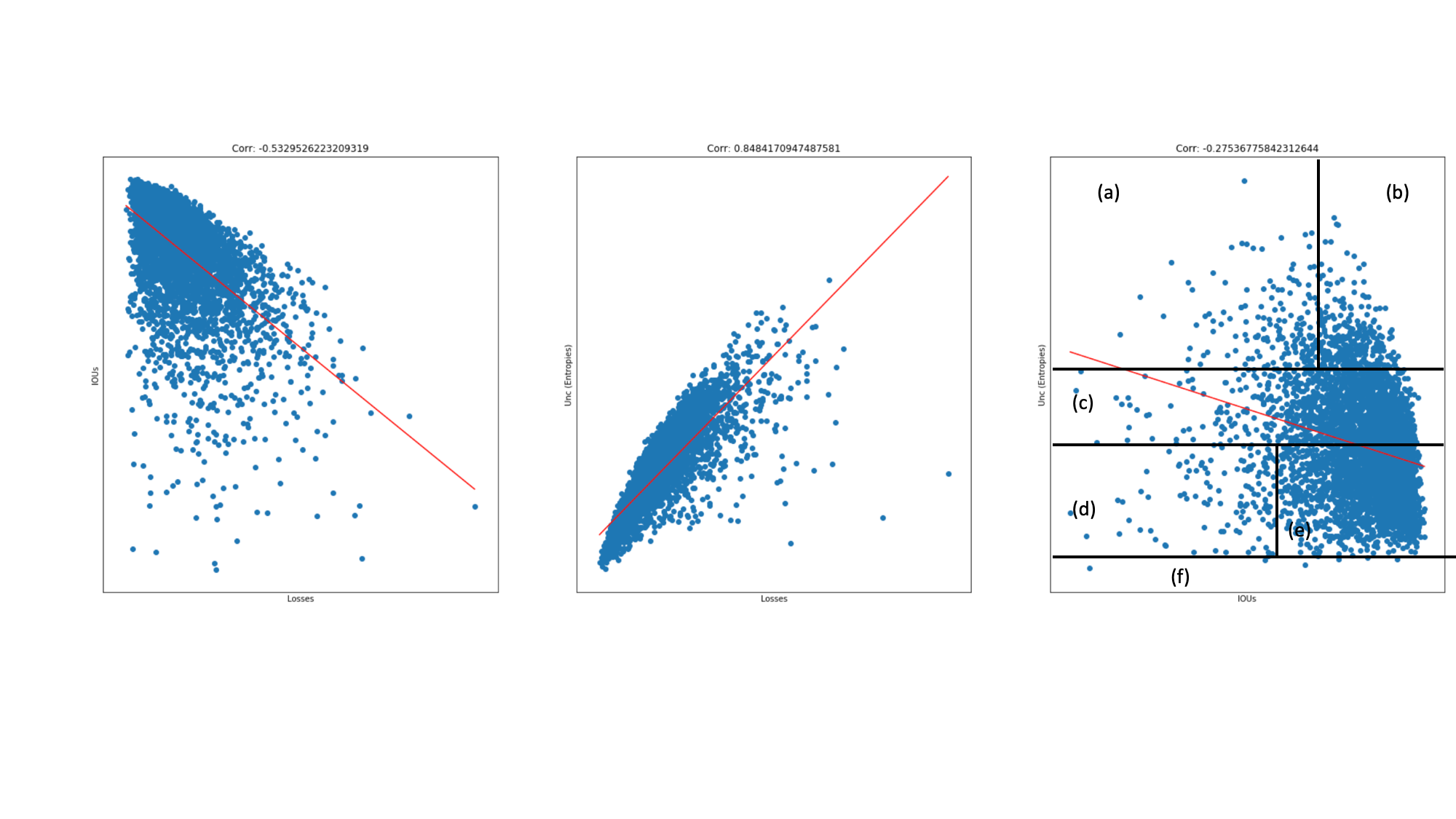
- a) High uncertainty, choose to annotate and will be most useful for model performance,
- b) High uncertainty, choose to annotate and will be not be as useful as (a) since samples already have high IOU.
- c) Medium level uncertainty, not so certain how to use these samples, most likely ignore.
- d) Low uncertainty, choose to psuedo label but it may degrade model performance by feeding systematic error.
- e) Low uncertainty, choose to psuedo label and will be most likely helpful in improving model performance.
- f) Low uncertainty and low IOU. May these be samples out of training distribution? See this blog
Maybe diversity sampling can be made to collect similar images.
This is a very early stage work to get an initial understanding. Entropy as an uncertainty measure is probably not the best one, especially compared with Dropout / Ensemble / Bayesian Network based uncertainties.
Next: Investigate Dropout and Ensemble uncertainty methods.