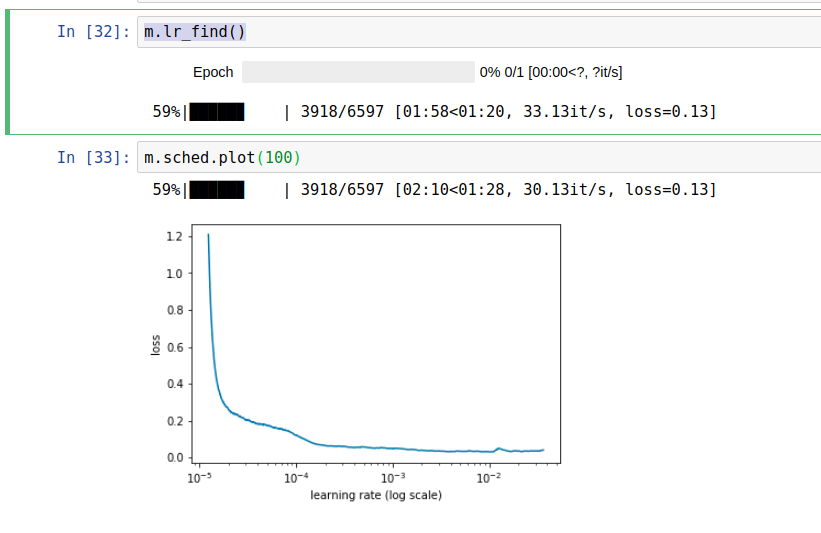
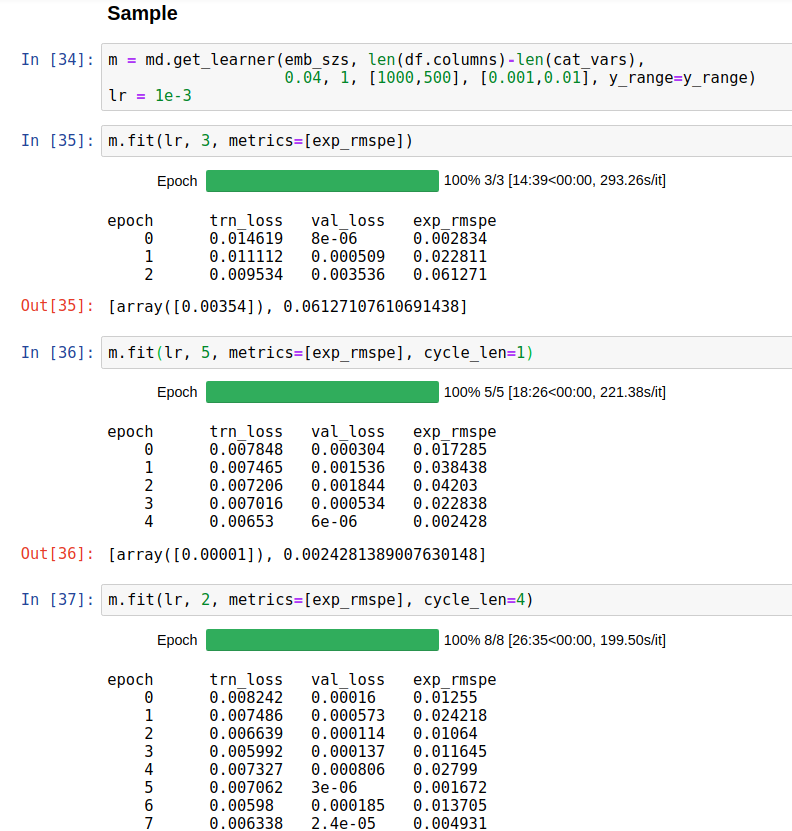
For dropout parameter, I wonder why it is so small. emb_drop = 0.04 ; drops = [0.001,0.01]. It means that the model is very easy to overfitting because we drop almost nothing.
This is the first time I attack the structure learning. I am very appreciate if someone can help me to clarify these problem. Thank you so much
I post the same question at Wiki_lesson4 and get the answer. The reason why the exp_rmspe is so small comparing to the original notebook is because of setting val_idx=[0] before learning. If someone try to run the notebook in order, should comment this line to get the proper results.