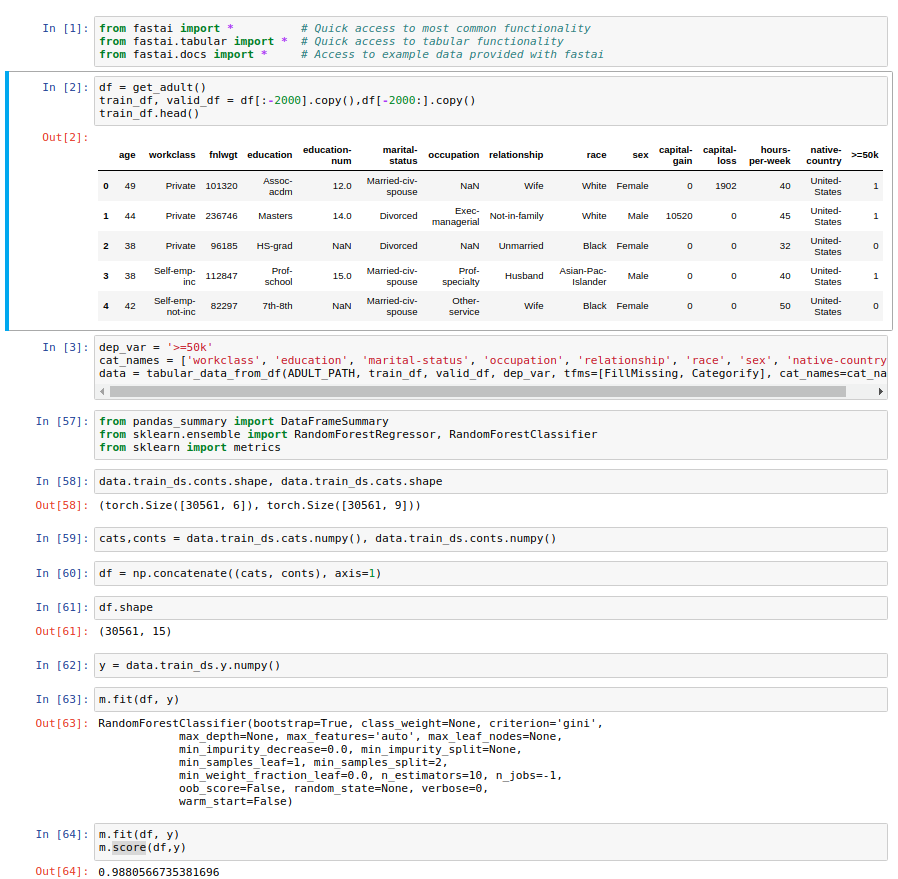
If someone just need the preprocessing part in Tabular Module and use another algorithm (random forest, …). It is easy to do so.
In tabular data set, you are likely have some non numeric data (text). However random forest module from sklearn need the numerical data. Fast.ai tabular module can handle it for you  . There is a normalization part that is not necessary in random forest, but I think it is not a big deal.
. There is a normalization part that is not necessary in random forest, but I think it is not a big deal.
The code is in the picture below (I don’t know what is the better way to embed a code from jupyter notebook here).
Hope that helps