I found that the tabular module is hard for learner to undertand (including me when I watched the lecture 4 in Fast.ai course v2). There are several topics asking about its concepts in the forum.
After playing around with the fast.ai 1.0 library, I created this Kernel : revese_tabular_fastai in Kaggle that I was trying to rewrite the Tabular Module in pytorch with minimum of code and explanation (similar to the approach of the 001a_nn_basics notebook).
I think it migh be helpful for someone who did the course last year and want to really understand deeply the concept of using deep learning with tabular dataset.
First of all thank you for taking up this interesting topic. Sorry but the link dosent work
Ok, i was curious to know if you could implemented the tabular module in the Kaggle Kernel because i did try it like 2 - 3 weeks back but it was not working when I would use the GPU and was giving in some problems. and honestly i could not complete it with CPU either. It would be very interesting if you could share the notebook here.
If someone just need the preprocessing part in Tabular Module and use another algorithm (random forest, …). It is easy to do so.
In tabular data set, you are likely have some non numeric data (text). However random forest module from sklearn need the numerical data. Fast.ai tabular module can handle it for you . There is a normalization part that is not necessary in random forest, but I think it is not a big deal.
The code is in the picture below (I don’t know what is the better way to embed a code from jupyter notebook here).
Thank you @jeremy. You can find here my twitter account DienhoaT. I just started to use twitter It is so good to update new tech. I haven’t tweet anything yet and so happy if you will share my work !
@dhoa Thank you for the great work and explanations. I found it very informative.
Unfortunately it seems the api has been updated and this method of preprocessing no longer works. For example, data.train_ds has no attribute cats and conts anymore. I only see .x and .y as options which return a Tabular list. Have you found a way to still return a DataFrame after this change? I’ve been looking in the docs and source code for the last day or so and keep coming up empty.
This is how I created my databunch since I needed to use the DataBlock API to add a test set.
I’m quite busy in this moment and not working with tabular dataset. I haven’t ran any code with tabular data yet with the new API so I think I can’t help you now.
I will go back to it when I have time . Sorry and hope you will find a way to solve it
I had the same question so perhaps you’ve figured it out already, but it might help others to have the most current solution.
I think one would go about it like this: cats = data.train_ds.x.codes #cats is now a numpy array conts = data.train_ds.x.conts #conts is now a numpy array
and then: df = np.concatenate((data.train_ds.x.codes, data.train_ds.x.conts), axis=1)
Thanks for this! I have a newbie question: what if my csv file is already in the same directory as my notebook. What do I put in path? It doesn’t allow me to leave it empty.
@muellerzr Thanks! Path works now. But all of my variables are categorical, so it throws this error:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-73-ac4a10b367e4> in <module>
----> 1 data = TabularDataBunch.from_df(path='.', df=df[qual+dep_var], dep_var=dep_var, valid_idx=valid_idx, procs=procs, cat_names=qual)
2
/usr/local/Cellar/jupyterlab/2.0.1/libexec/lib/python3.7/site-packages/fastai/tabular/data.py in from_df(cls, path, df, dep_var, valid_idx, procs, cat_names, cont_names, classes, test_df, bs, val_bs, num_workers, dl_tfms, device, collate_fn, no_check)
90 "Create a `DataBunch` from `df` and `valid_idx` with `dep_var`. `kwargs` are passed to `DataBunch.create`."
91 cat_names = ifnone(cat_names, []).copy()
---> 92 cont_names = ifnone(cont_names, list(set(df)-set(cat_names)-{dep_var}))
93 procs = listify(procs)
94 src = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
TypeError: unhashable type: 'list'
Seems like the default calculation it is doing for cont_names fails, and just manually trying to set it to None or an empty list results in the same outcome – how can I force it to have no continuous variables?


 it should works now. Tell me if you need any further information.
it should works now. Tell me if you need any further information. . There is a normalization part that is not necessary in random forest, but I think it is not a big deal.
. There is a normalization part that is not necessary in random forest, but I think it is not a big deal.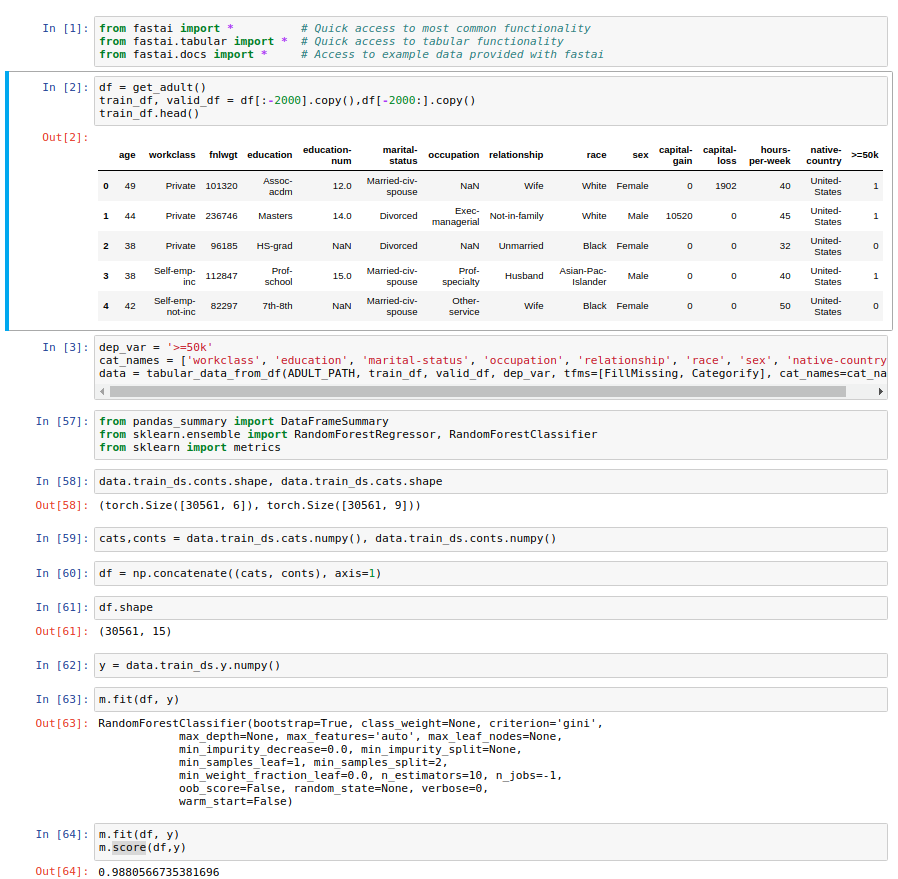
 . Sorry and hope you will find a way to solve it
. Sorry and hope you will find a way to solve it