This paper from TenCent was just posted about 3 days ago…and I set it up with MNIST and got good results so moving it to XResNet next to test with ImageNette.
Anyway, wanted to post the paper here for others to review and see what you think.
A simple summary:
Current Norm:
weights->batchnorm->Relu
New IC style:
Relu->IC layer (batchnorm + dropout)->Weights
highlights: " we propose to implement an IC layer by combining two popular techniques, Batch Normalization and Dropout, in a new manner that we can rigorously prove that Dropout can quadratically reduce the mutual information and linearly reduce the correlation between any pair of neurons with respect to the dropout layer parameter p.
As demonstrated experimentally, the IC layer consistently outperforms the baseline approaches with more stable training process, faster convergence speed and better convergence limit on CIFAR10/100 and ILSVRC2012 datasets.
The implementation of our IC layer makes us rethink the common practices in the design of neural networks. For example, we should not place Batch Normalization before ReLU since the non-negative responses of ReLU will make the weight layer updated in a suboptimal way, and we can achieve better performance by combining Batch Normalization and Dropout together as an IC layer."
I’m hoping to have some ImageNette test results to compare vs leaderboard soon.
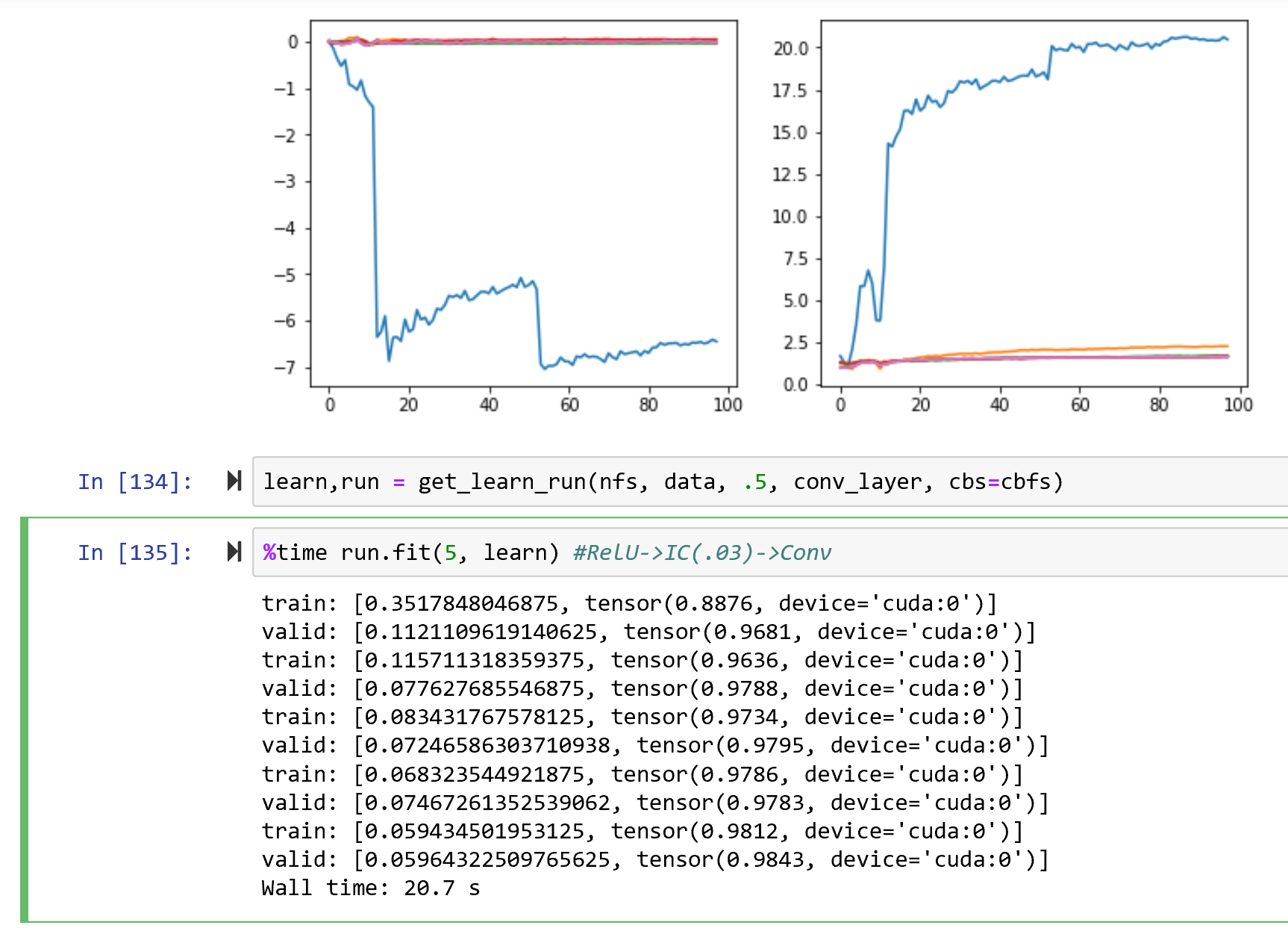
I spent more time on MNIST to try and understand it better. The paper recommended .05 - .10 for dropout in the IC, I got better results with .03.
It’s also clear that while a lot of the improvements are from dropout alone, the combination of BN+Dropout is synergistic and outperforms either alone.
They do seem to be correct that having this IC layer (the combo of dropout and BN) does make it generalize better as validation results were consistently equal or better than training, vs the normal Conv->BN-Relu almost always did worse on validation.
I did a bunch of other tests trying out different activations, etc. but the above is pretty representative of the difference.
Note that I was hoping that the graphs of the mean/std dev would be predictive, but I really didn’t see much correlation to the smoothness or range of those numbers and the actual results. The only thing was a large spread in SD did mean risk of hitting NAN gradients so you have to watch the learning rates more closely.
Anyway, I’ll try and setup for ImageNette next to see if this continues with more realistic data sets than MNIST.
Looking forward to your Imagenette results. Remember there is a lot of variance in the results, so you might have to run things a few times (even for the baseline). Also, Imagewoof is harder, so you might have an easier time seeing difference with it.
I skimmed over the paper. Lots of theory, but in practice it looks quite simple.
It looks to me that they are doing 3 things together:
Place BatchNorm after ReLU
Add dropout right after BatchNorm
Try 3 different placements for the skip connection. (Results seem inconclusive on which placement is best. Also, their idea of combining BN and dropout prevents them from trying the 4th option which is to have the skip connection between BN and dropout)
basically I put this in the cell above the ResNet block so it uses that vs the one from the notebook import.
My thinking was if we only put in the IC layer only when it has an activation function…but not sure if that’s correct yet.
Note - you will have to change the act_function to remove the (inplace=True) as it will balk about it losing graph tracking if you do it inplace, since it’s now in front instead of at the end: act_function=nn.ReLU()
Is the plan to modify the ResBlock module to use act = True everywhere and the remove the act_fn in forward()?
Also you might have to deal with the extremities of the architecture. Maybe removing the activation+IC in the first conv_layer of the stem (XResnet class), and adding it after the last conv_layer of the network?
Hi Seb,
My plan is to better understand resnet today lol - i.e. to rewatch the video (lesson 12?) today on XResNet building, revisit the paper, and verify if that does the right thing or I need to better place the IC layer.
For now I ran it last night 2x on ImageNette (as coded above) and got the following validation accuracy with .05 dropout:
Start Epoch 10
24.4 74.20
20.0 76.00
dropout of .05
LR = 1e-3 / XResNet34
However, I see that SGugger made a checkin about 2 weeks ago to fix/update the XResNet (extra conv layer in the resnet block) so I’ve updated with that.
And after reviewing the XResNet Code again, can see that my first attempt at the IC conv layer needs improving. I’m now running with this:
Well, I clearly don’t have it fully setup properly.
I’m testing with pure XResNet34 / Imagenette -160 now as the control, and it’s ended with 87.2% vs the best so far with IC is 74-76% after 10 epochs
So I need to better understand the ResNet architecture and update the conv layer appropriately. IC is an improvement in simple conv models so in theory the issue here is I don’t have the blocks setup right in our XResNet.