Hi.
After Lesson 1, I’ve created my own dataset of Jaguars and Leopards. As you may know, these 2 cats are incredibly identical and difficult to tell apart even for humans. I felt that it was a good problem to approach. I created the dataset with pictures of Leopards/Jaguars and their cubs. I’ve excluded black jaguars/leopards from the dataset as the main distinguishing factor between the two cats are their spots as far as the pictures are concerned. There are 2330 pictures in total. About 900 of them are Jaguars and the remaining 1430 are leopards.
When I applied ResNet50 on this dataset, this is what I got
epoch train_loss valid_loss error_rate time
0 1.243817 1.034391 0.221030 01:47
1 0.903427 0.573112 0.145923 01:43
2 0.624625 0.443679 0.111588 01:45
3 0.475609 0.424810 0.109442 01:45
After going through the entire process as the Lesson, this was the final output:
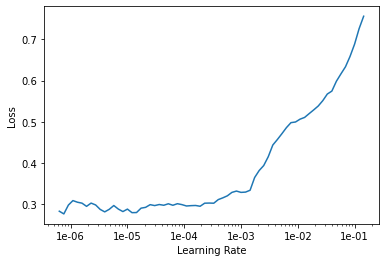
epoch train_loss valid_loss error_rate time
0 0.331031 0.417951 0.111588 01:43
1 0.310243 0.417044 0.111588 01:44
I tried using ResNet101 but Colab threw a RuntimeError: CUDA out of memory error.
What are some of the ways I can improve this? Do you think an imbalanced dataset contributed to such a high error rate?
Here is the full dataset: https://github.com/oo92/jaguar-leopard-classifier.git