The fastai dawnbench results have been beyond extraordinary It is also very impressive how quite a few people were able to come together to make this possible.
I am trying to reproduce the results locally on my own machine. I was able to train a wide resnet in 40 epochs to 94% accuracy, but I am not sure if those were the settings that were used for the submissions?
I tried looking around in the repo but I didn’t get very far. With a learning rate of 2 and a batch size of 128 the training was diverging (but maybe I messed up something else along the way).
Could I please ask what settings were used for the submissions, especially in the single GPU case? Both for the cifar10 and imagenet? Also, was there any warming up done?
I think if I would be able to train imagenet on a machine with a single 1080ti anywhere under a day (under 12 hrs would be a dream) that would be amazing and very useful for trying out architectures, etc (for example, I would like to train a model with attention and compare it to one without).
Contrary to what has been told recently on twitter, the batch size is everything in this case. With 128, you won’t be able to get to as high learning rates without experiencing divergence in your training.
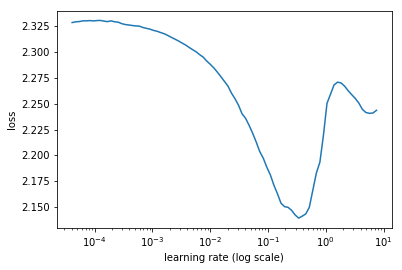
Like in your graph 0.3 or 0.4 seems safe, 1 might be doable but risky, 2 is too close to the minimum.
Don’t go make the same mistake as the people in the article I mentioned though: doubling the batch-size doesn’t imply multiplying the learning rate by 2 (or dividing it by 2 halfing it). This rule is for people who try to guess a learning rate without our LR Finder, and if there is one thing the article shows, it’s that it doesn’t work .
Just rerun the learning rate finder after changing the batchsize. Also, since you’re using weight decay, be sure to include that in your LR finder (by putting wds=wd as an argument) because that will also change your curve a tiny bit (maybe not too much, but let’s be as careful as we can). Then take the minimum of your curve and divide it by 3 if you’re bold (it still may diverge if your cycle is too short) and divide it by 10 if you want to be on the safer side.
Thank you very much @sgugger for a lot of great advice I often go back to the pms we exchanged and to your blog post - I now have another definite source of information in the form of the above post to add to my list Thank you so much!
This sounds like a lot of fun and seems a lot could be learned along the way! The end result might maybe be a notebook detailing how to get the data and process is appropriately (including moving things around per the script from Soumith) and from that point one would only need to hit run all below.
There is a treasure trove of information in the imagenet-fast repository. I now also believe it has all the information to mimic the way the DAWNbench submissions were made (including the imagenet one). Clicking the links where it says source on the DAWNbench results are a great entry point and from there it is just a little bit of detective work where all the info / defaults reside.
BTW seems argparse is used quite extensively - I have not used it before but sounds like something very useful in the context of machine learning. Hoping to look into this as well at some point Perusing the code should be a really good way to learn.
Anyhow - if I have anything ready - even should it be a scaffold to just get the data in order - I’ll post to this thread.
Training on cifar10 in 20 minutes and the training being contained in one chunk is so cool It literally feels fun and puts a nice structure around experimenting.
One thing I observed that is both interesting and might be useful to others. There are two wide resnet implementations in imagenet-fast, one in wideresnet.py and the other in wideresnet_new.py
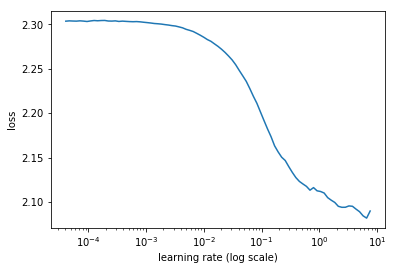
I am not sure what the differences in the implementation are, but they give very different results for the lr finder:
wrn_22 from wideresnet.py
wrn_22 from wideresnet_new.py
I am not sure what the differences in the implementations are. I think in the DAWN bench submission the wrn_22 from wideresnet.py was used and it was run with the following settings (to achieve superconvergence) with a batch size of 512: learn.fit(1.5, 1, wds=1e-4, cycle_len=30, use_clr_beta=(15, 10, 0.95, 0.85))
This doesn’t seem to always hit the 94% accuracy locally (those with these setts gets closer than the other resnet), but gets very close (on fp16 the cost function was slightly different, had scaling, maybe there are other differences as well, maybe it doesn’t have to hit 94% every time, who knows )
I think with very little warm up we can get this to 94% on personal DL rigs consistently, or maybe via tweaking the parameters a bit.
Anyhow - I am very excited about this. What 20 minute train time does to ones ability to experiment is beyond imaginable.
I believe for imagenet submission the main.py was run. I have not been able to find the arguments that it was run with though and the defaults are not what was used (it defaults to resnet18 for instance). Could I please ask if the arguments that it was run with could be shared please?
I also believe that the following transformation was used during training: transforms.RandomResizedCrop(args.sz, scale=(min_scale, 1.0)) with default min_scale being 0.08.
Does this mean that for all images we were keeping the aspect ratio, but we were taking a small piece of the image (up to just 0.08 of it - the calculation is a bit more involved as it looks at one of the sides etc but that is the gist of it I believe) and we were blowing it up to full dimensions? Towards the end of the training (last 8% of epochs) we use min_scale=0.5. Could I please ask if I am reading this correctly?
Amazing work for sure! Seems to me that sometimes having too many resources available can make oneself a bit lazy on focusing how to apply those resources more smartly. Based on your work (and fast.ai) I tend to believe that we will see ImageNet training on single gpu under couple of hours by the end of 2018
Very cool! You may want to try the approach from @bkj - resnet18 plus concat pooling. The wrn approach is better for multi-gpu, but no as good for single gpu.
It is interesting that I get considerably slower results. Trying to replicate with your parameters. Converges similarly but much slower, see below.
My hardware:
Intel i7-7700K@4.2GHz x 8(CPU) (actually 4 cores), 32GB of RAM
Zotac GeForce 1080Ti 11GB
MSI Z170I Gaming Pro motherboard
Wondering why such a difference? I suspect slow read from hard drive. I’ve got Samsung 500GB SSD Sata3. Otherwize my hardware should be at par with yours. You have much better motherboard, but i guess my cpu should be much faster than yours.
learn.fit(1.5, 1, wds=1e-4, cycle_len=20, use_clr_beta=(12, 15, 0.95, 0.85))
my time:
CPU times: user 17min 27s, sys: 7min 10s, total: 24min 38s
Wall time: 20min 30s
your time:
CPU times: user 9min 10s, sys: 4min 26s, total: 13min 37s
Wall time: 13min 29s
learn.fit(1.5, 1, wds=1e-4, cycle_len=30, use_clr_beta=(15, 10, 0.95, 0.85));
my time:
CPU times: user 21min 54s, sys: 11min 13s, total: 33min 7s
Wall time: 28min 31s
your time:
CPU times: user 12min 6s, sys: 6min 45s, total: 18min 51s
Wall time: 18min 55s
 It is also very impressive how quite a few people were able to come together to make this possible.
It is also very impressive how quite a few people were able to come together to make this possible. .
.