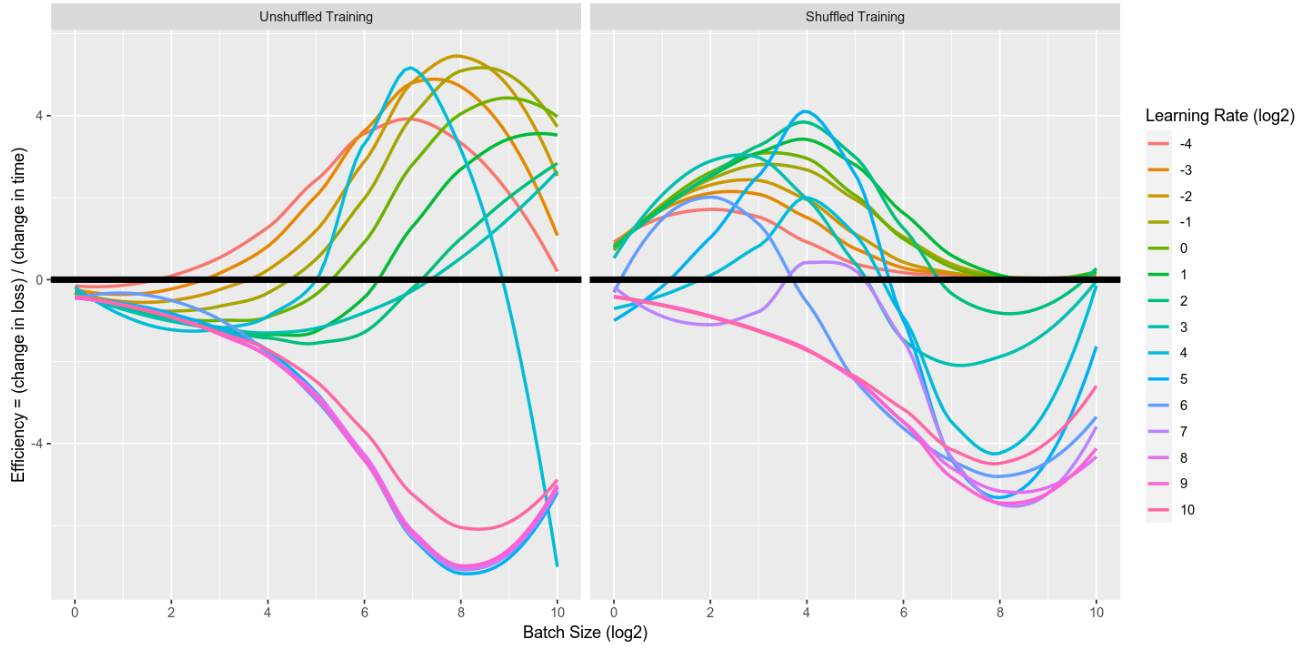
Question. Why does the best batch size and learning rate vary so much depending on whether the data is shuffled or not?
I am working on hand-coding the 3 vs 7 image classifier from Chapter 4. I have a working classifier now. To debug it, I needed to investigate the relationship between learning rate and batch size.
The original data in the book is presented “unshuffled”, so all of the 3’s in the training set appear first, then all of the 7’s.
The graphs below show data gathered from a handmade SGD process:
x-axis: batch size (log2), so x=4 corresponds to a batch size of 2^4 = 16
y-axis: training efficiency, computed by dividing the change in accuracy (subtracting percentages) for the first epoch by the amount of CPU time used to train (no GPU, used time.process_time_ns())
colors show the learning rate (log2), so color=3 corresponds to a learning rate of 2^3 = 8
I think the best (batch size, learning rate) pair to use corresponds to points highest on the “efficiency” scale. For example, (4,5) looks like the peak, which is a batch size of 2^4 and a learning rate of 2^5.
Generally, larger batch sizes have more consistency in producing the result i.e the model sees more data in a batch, hence learns more things about it and produces a result based on that. This learning is carried forward for the epoch where at the end the loss function calculates the loss and the weight is adjusted to repeat the process. The learning rate being larger for large batch size means, there is a chance it will skip over the minima and increase the loss.
As for the shuffling of data, it’s mentioned that the experiment was only over a batch. At the end of the epoch, the performance of the model with the data with and without shuffling should more or less converge. Generally in deep learning, there is an inherent randomness in initialising activations which can sometimes lead to inconsistencies. But in the bigger picture, this inconsistency should be marginal and would not cause any major performance swings
This response sounds good as far as it goes, but I don’t think it addresses any of the issues in my post.
In particular, the question asks for conjectures why shuffling has such an impact.
The post is about how to balance batch size and learning rate to maximize learning “efficiency”. If you make small amounts of progress in each batch, but the batches run quickly, that can be better than large progress in a few slow batches.
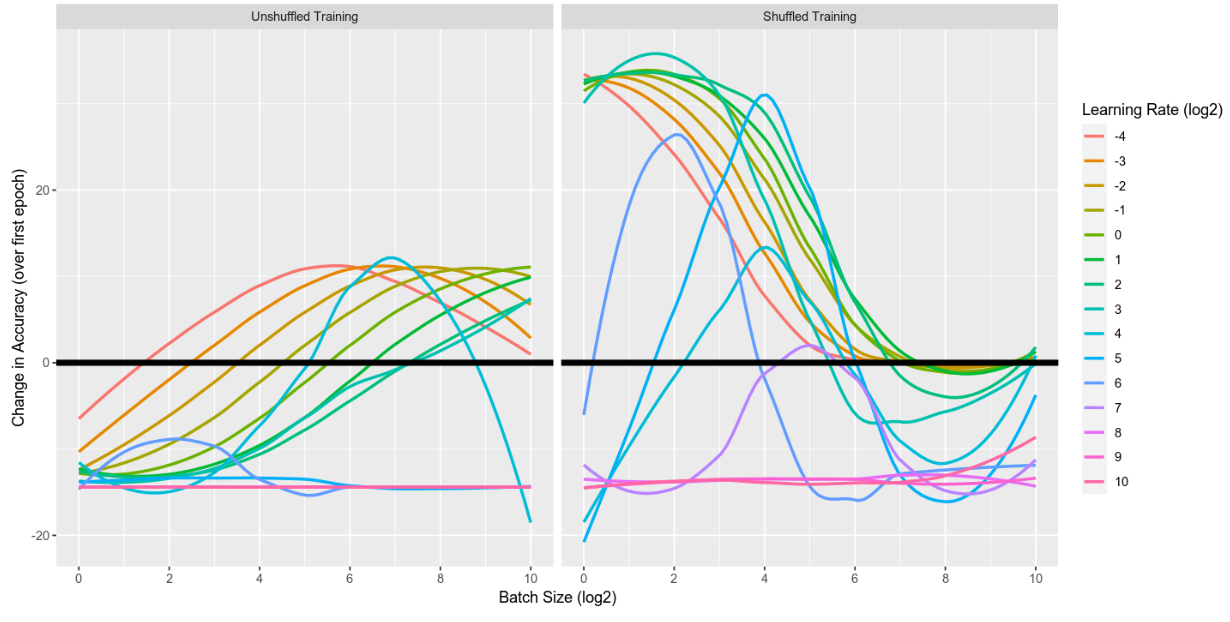
Surprisingly to me, the total change in accuracy (not efficiency) over a single epoch is affected a lot by the shuffling (as well as batch size). (Rememer the training data is sorted by default; all of the 3s then all of the 7s.) Is this expected? Can you explain it? Graphs of change in accuracy below.