Well, this topic had been mentioned before here but since the thread is inactive, I’ll post it again.
The lr_find method mentions that it uses the paper Cyclical Learning Rates for Training Neural Networks to find the optimal learning rate but, the actual purpose of the paper is to remove the need to guess any learning rate whatsoever.
Here is a quote from the abstract of the paper:
This paper describes a new method for setting the learning rate, named cyclical learning rates, which practically eliminates the need to experimentally find the best values and schedule for the global learning rates.
And according to lr_find, it uses this same paper to find the optimal learning rate.
Also, cyclical learning rate is a scheduler to vary the learning rate during training rather than to find the optimal learning rate before training the model.
The paper only describes mechanism to find this lr interval (max_lr and base_lr) but doesn’t mention anything about the optimal learning rate. And for this, it uses the accuracy vs lr plot rather than using the loss vs lr to find the lr interval.
Here is the figure:
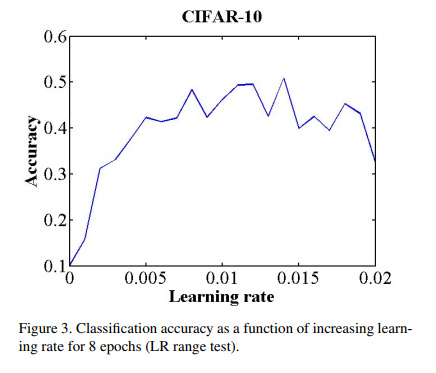
Also, like jeremy mentions, it doesn’t even use the steepest incline as the max_lr but actually recommends it as:
Next, plot the accuracy versus learning rate. Note the learning rate value when the accuracy starts to increase and when the accuracy slows, becomes ragged, or starts to fall. These two learning rates are good choices for bounds; that is, set base lr to the first value and set max lr to the latter value
It merely says to use the first lr that it finds as base_lr and then use the lr when the accuracy begins to become jagged as the max_lr.
It may just be that I don’t know much and as such I really can’t understand this paper or that maybe Jeremy misquoted the paper?
If anyone knows where the optimal learning rate finder paper is, a little help would be greatly appreciated.

