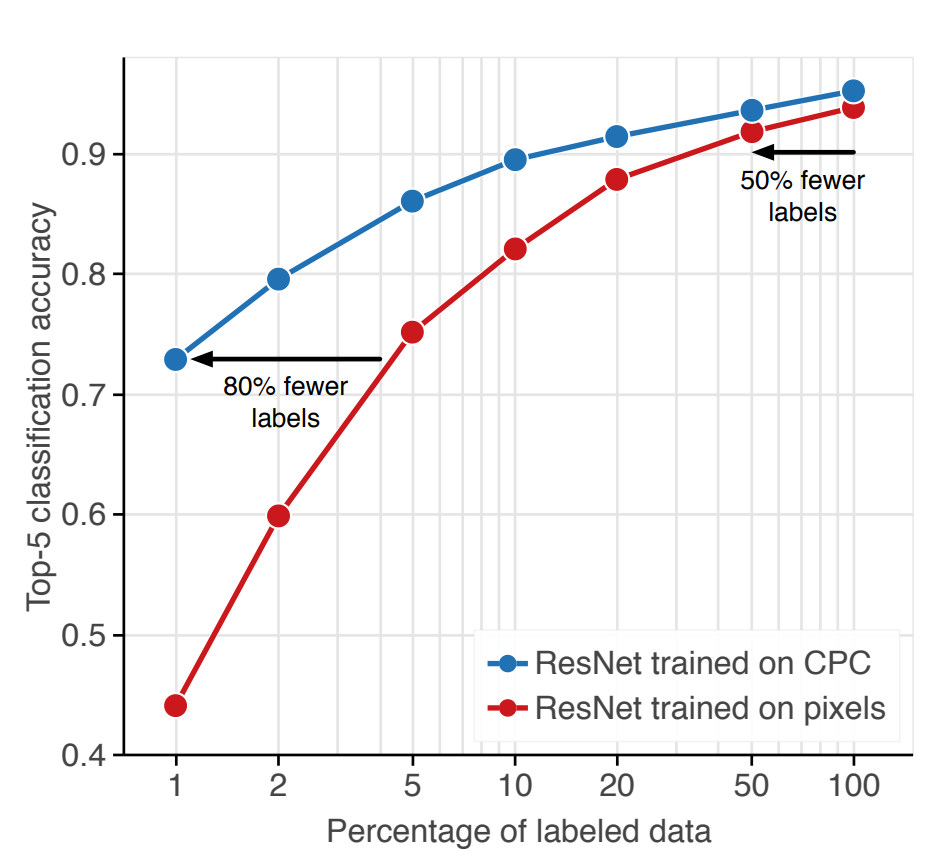
DeepMind published a new paper called “Data Efficient Image Recognition” and introduced CPC 2.0. They accomplish new state of the art on object recognition via transfer learning a CPC trained ResNet and more importantly, set new milestones for training with 2-5x less data:
CPC for vision is basically taking an image, clipping it into overlapping patches, creating feature vectors from each patch and then training the NN by asking it to pick a feature vector from the bottom of the image amongst a series of negative feature vectors from other images.
In other words, it helps it build better representations of the objects in the image.
I wrote a summary article with more info here:
And full paper is here:
The authors indicate CPC 2.0 will be open sourced soon, so hoping we can look at integrating it into FastAI 2.0
In appendix A.2 on page 14 in the publication they have outlined the setup in pseudo code. Looks quite compact but you have to be careful to keep track of the tensor dimensions.
The setup reminds me of language model pretraining for image data.
However, I am still struggling with the labels part below in the code, i.e., b, col, labels, and loss calculation. Maybe somebody else is also trying to make sense out of it and wants to discuss it?
Thanks for posting this @MicPie - now I’m very interested to checkout the ‘fine tune’ option in FastAI2.
There’s another paper out on using weakly labeled data first and then using less than 10% of labeled data, meet or beat SOTA. I’ll try and post that paper out shortly (need to find it again).
Looked at the source a bit more as I said that. The freezing runs at 2x the base learning rate chosen, and the training starts with the tail end of one-cycle before unfreezing
It is hard to keep up with the output of publications from Google & Co.
(We need another thread for papers like that to share & discuss. #toolongreadinglist)!
Hi MicPie Hope your having a wonderful day!
Wow a very enlightening and informative post, I am convinced we need to change IP as a metaphor human brain.
I was just reading about that today. I wonder if it has some applications in the text/tabular realm too (curious to see if anyone starts playing with it)