Hopefully, this is the right place, it is my first pull. I recently used a memory saving function to help out with a monstrous dataset on Kaggle. Thought it would be useful for the library.
It moves dtypes of a DF to lower values when possible.
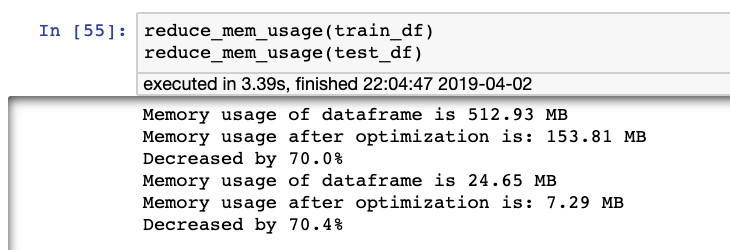
I replicated it on Rossmann to show benefit and prove it works.
Biggest Benefit
Reduced mem usage by 70%. Understand Rossmann isn’t gigantic but very helpful on the recent Kaggle Microsoft Challenge to get 8 GB to 2GB.
Performance on default Batchsize
Similar speed and performance.
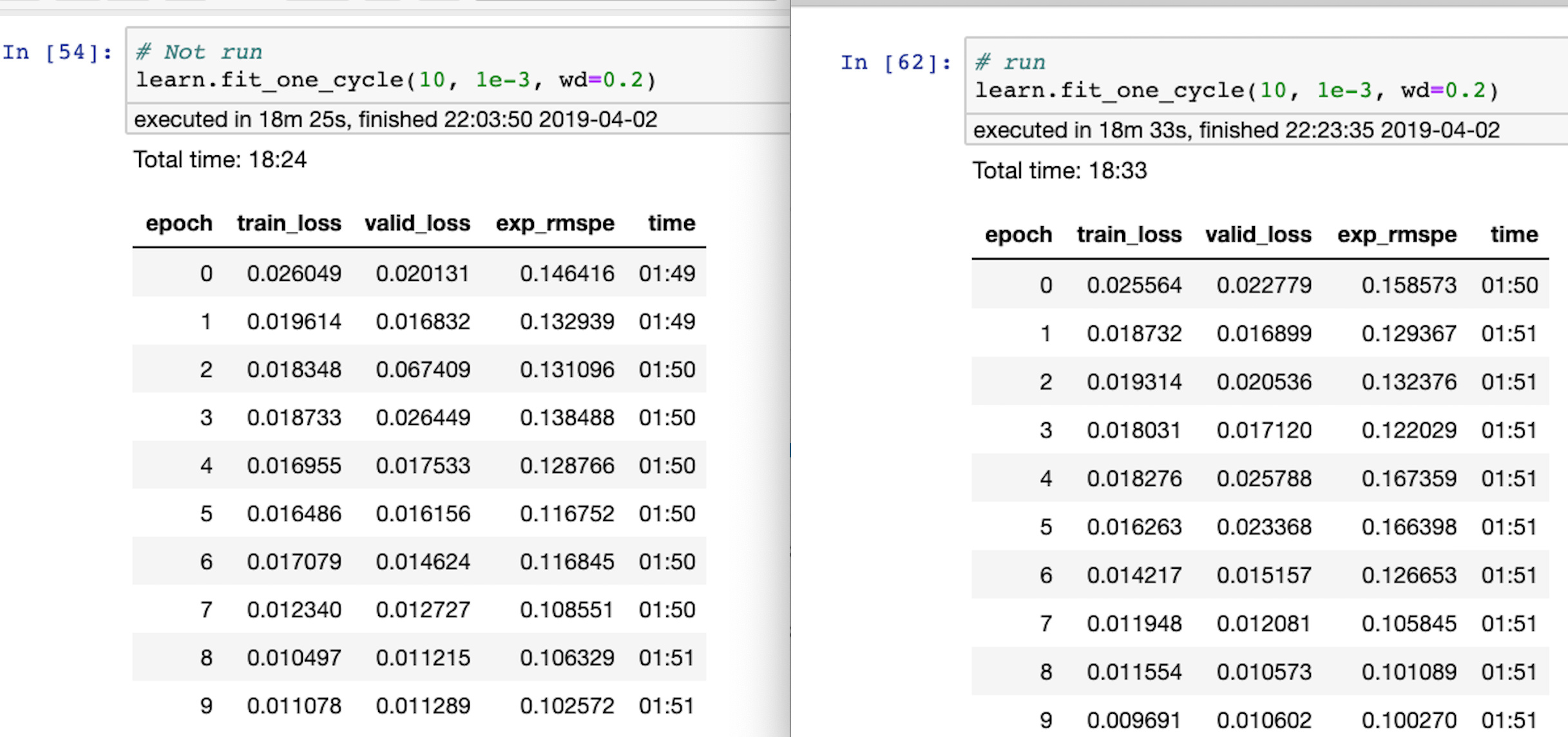
Of course, lower memory would allow more batch sizes to be run simultaneously.
Caveat: Might need some help tweak reducing variables to Float16. For whatever reason, it crashes the Rossmann dataset when I test it.