(not sure if ML topics fit in this section of the forums but I see nowhere else to ask this)
I have been trying to use Random Forest to analyze some data on paragliding free-flight (mainly trying to find predictive indications from weather data (pressure, temperature, humidity, etc) on cross country flight distances). I started using Neural Networks but took a step back and am now testing regressions and random forest.
I have a couple of questions regarding RF:
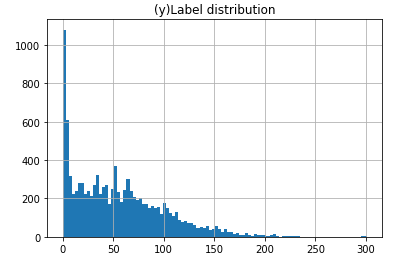
Does it make sense to attempt to normalize the data for a random forest? Or is it unnecessary given that the model has different assumptions from a typical regression? The image below shows my dependent variable (flight distance) for example.
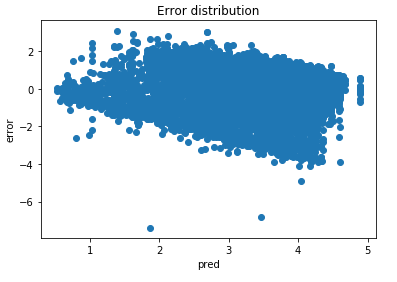
Does it make any sense to analyze the errors of predictions made by a random forest ensemble? Can I get relevant information by analyzing this? Below an image of my latest model which clearly shows a tendency in the errors. My assumption is that there is some hidden factor which I am not taking into account in my model (my best guess right now is: pilot experience).
edit:
Is it safe to assume that the most important features pointed out by a RF are also the important features whichever predictive model I use? In other words, can I safely ignore non-important features when building Neural Nets or other models?
Normalizing features with global statistic does not make difference, as you may understand the nature of RF is a linear classifier, as long as it is a monotonic transformation (order is preserved, that’s mean only orders matter), it will make no difference.
It always make sense to do error analysis, as interpretation is often more important than prediction itself.
Gian, I’ve recently started working with RFs myself, but here’s my input:
Normalization is not required for RFs because each node in the tree is simply splitting a sorted list and not comparing one feature’s value to another feature’s value. Neural Networks on the other hand do need data normalization.
Your results look kind of random. I suggest going through the code step by step and verifying you don’t have a logic bug and the data at each step looks correct. Did you write your own RF class or did you use a library?
I don’t have data to prove it, but my instinct is that you should let the model decide which are important and which are not. So if you switch from NNs to RFs, run all of the features through the RF and then do feature analysis to figure out which are important.
thank you @nok and @sjjohns for your inputs! I have a better understanding now of how the RF algorithm works and how, since it is basically building separations and not doing calculations on the inputs their values (‘normality’) is not relevant.
@sjjohns yes my results are terrible atm… I still have some ideas for feature engineering but there’s also the possibility that I cannot predict what I want with the data I have. I am using sklearn.
I have a question about random forest as it is my first time. I have watched perheps 30 videos on youtube about it and have “good” understanding.
However there is one thing that I never get a clear answer on how to do correctly and that is:
How to correctly build a tree from features?
First question:
Assume we have randomly selected 7 features to create a tree. Now we should start the rootnode with the feature with the highest GINI index for example. I wonder then if we after the rootnode continue in a greedy fashion to the leafnode or do the other 6 features have random selected GINI indexes and it doesn’t matter in what order they come?
Second question:
Must all 7 features be used always in Each tree? What I wonder is if my hypothes says TRUE for any feature before I have been able to use all 7 features in the tree. Should I then STOP building the tree here? - or even that a node says TRUE for the hypothes, should I continue until all 7 features are used and then go on what the leaf node says, TRUE or FALSE?
It was a bit unclear to me what you are asking, I try my best to guess what you are asking.
For the second question, each feature have a probability to be used in every split, that is what the max_feature does. If one node is sufficient to classify something to True(I guess here u mean the label for a classification problem). Then further gain from the other 6 feature will be essentially 0, thus no further split should be happening.