I’m working on an image segmentation task with multiple labels. Here’s how I’ve set up the data bunch:
class MultiClassSegList(SegmentationLabelList):
def open(self, id_rles):
image_id, rles = id_rles[0], id_rles[1:]
shape = open_image(self.path/image_id).shape[-2:]
final_mask = torch.zeros((1, *shape))
for k, rle in enumerate(rles):
if isinstance(rle, str):
mask = open_mask_rle(rle, shape).px.permute(0, 2, 1)
final_mask += (k + 1) * mask
return ImageSegment(final_mask)
def load_data(path, df):
train_list = (SegmentationItemList
.from_df(df, path=path/"train_images")
.split_none()
.label_from_df(cols=list(range(5)), label_cls=MultiClassSegList, classes=[0, 1, 2, 3, 4])
.transform(get_transforms(), size=imgsz, tfm_y=True)
.databunch(bs=bs, num_workers=0))
return train_list
On training, my network was performing very poorly. After inspection, I found out this-
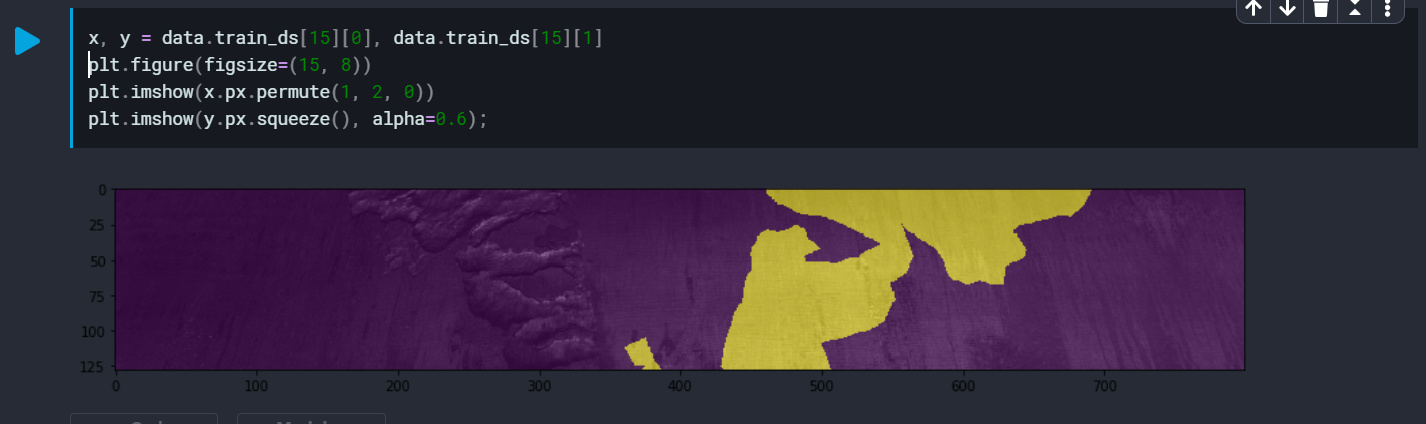
The actual mask should be the mirror image of the current one (it should cover the rough surface). But as you can see it is way off than where it actually should have been. I’m not sure if I’m setting it up wrong?
I’m not sure it works for me and the only thing I am doing differently is splitting the data, which should not have effect on this. Seems that the image was flipped but the mask wasn’t, which is pretty strange.
Yeah. Very strange. I spent some time debugging but couldn’t find out why. I tried using split_by_random as well but still facing the same issue.
Or maybe I’m visualizing it in the wrong way? Maybe I’m not supposed to call the data.train_ds[x] manually. For instance, even if I try to fetch only the ys using data.train_ds[x][1] I get a different output every time.
Aaaaah yes, found out why. You had the correct intuition, I didn’t even notice the error at first. Everytime you write data.train_ds[i], it will open the corresponding image and apply some random transforms to it. So when you write x, y = data.train_ds[15][0], data.train_ds[15][1], it loads the 15th image twice, applies random transforms to both (not necessarily the same ones), and then it gives you the image loaded from the first call and a mask that didn’t go through the same transforms because it was loaded by the second call. To sum it up, what it does is:
- Go fetch the 15th image of the dataset
- Apply transforms to it
- Take the element 0 from the returned tuple (which is the image) and put it into x
- Go fetch the 15th image again
- Apply other random transforms to it
- Take the element 1 from the returned tuple (which is the mask) and put it into y
So of course it won’t match. The correct way to assign them is through unpacking: x, y = data.train_ds[15], which does the same thing as:
tuple = data.train_ds[15]
x = tuple[0]
y = tuple[1]
By opposition, what you wrote does:
tuple = data.train_ds[15]
x = tuple[0]
tuple = data.train_ds[15] # which is not the same
y = tuple[1]
2 Likes