Inspired by the winner of the Porto Seguro Kaggle competition, I found this paper that outlines an intuitive approach to using Random Forests as an autoencoder. It performs very well at recreating the MNIST and CIFAR-10 data sets.
The prediction of each tree on a data point corresponds to a decision path within the tree. By collecting those decision paths (the encoding), you can create a set of rules that restrict the possibility of the data point which produced them.
If you’re interested in translating their technique to python (after finals, of course), lets talk! Could be something we open-source (good for resume).
pretty cool idea. i’ll read. heh a simple and cool idea for encoding:
“Given a trained tree ensemble model of T trees, the forward encoding procedure takes an input data and send this data to each root node of trees in the ensemble, once the data traverse down to the leaf nodes for all trees, the procedure will return a T dimensional vector, where each element t is an integer index of the leaf node in tree t.”
hmm…this paper makes MCT ( maximum compatible tree) sound expensive as hell. no indication how they construct Maximal-Compatible Rule (MCR) but I assume via those trees.
Agree on MCT/MCR seeming expensive. However, from my understanding, you could create a decent MCT/MCR from only a fraction of the trees.
I’ve also thought, instead of using an entire decision path to construct the Maximal-Compatibility Rule (MCR), what if you only considered the first (root) split from each tree for encoding? n trees would result in an n element binary representation of the data point. Coupled with extremely randomized trees (ExtRa Trees), which is supported in scikit learn, I think this could make the MCR relatively cheap to calculate while being effective.
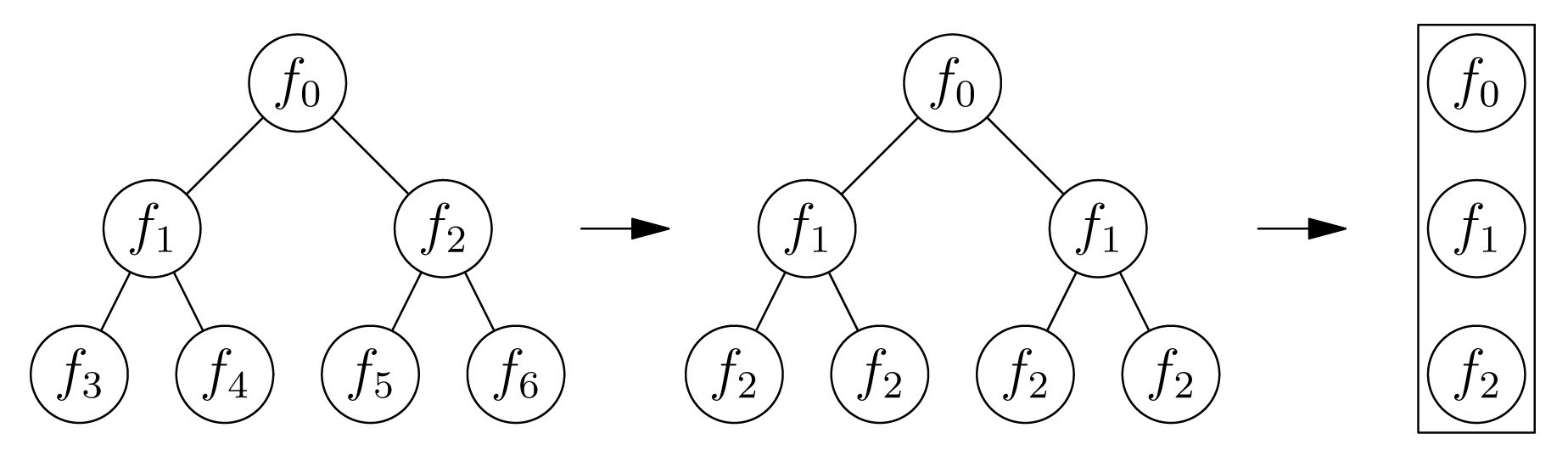
Going a step further, this binary encoding can be translated into a sort of ‘fern’ decision tree, where each node of the fern at level n represent n distinct rules for your MCR. A fern has the same split criteria applied at every node of same level (graphic below) I think the benefit here could be interesting–if you had 100 ExtRa trees in the forest for data with 100 columns, you’d get a fern that is potentially 100 levels deep. But lets say you get a new data point missing 50% of those columns, you could still create an MCR for prediction by extracting the rules from the fern for the data points you do have… just thinking out loud.
interesting. count me in for helping try to bash your way to victory on this. I’d love an RF-based auto-encoder. 'specially for NLP use. after your final!
Hey Ryan, outside of that , there’s also the NIPS implementation challenge. I just saw it posted on the DL side of the forum, take a look, that might be interesting as well.