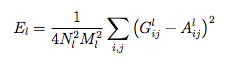I’m rereading Gatye’s paper and I’m confused at the style loss function, why are we dividing it by 4?
N means the number of filters
M means the feature map size, height * width
The equation represent"the mean-squared distance between the entries of the Gram matrix from the original image and the Gram matrix of the image to be generated.".
Thanks! I just studied your code again and noticed that you took care of (1/(N**N)* (M*M) in the gram_matrix function, essentially moving them inside the summation, I think it’s quite clean and elegant.
Compared your code with Fchollet’s implementation, I think he made a mistake by using channels instead of the number of filters. This also showed up in titu1994’s implementation.
This difference can impact the results because the filter number changes as the network moves to the deeper layer, hence regulating the strength style_loss.
If we just use the channels, it is fixed across all layers.
Hi - I’ve just finished lesson 8 (loving the course!), but I’m actually confused at why the style function isn’t that explainable.
I may easily be missing something, but doesn’t the diagonal of the gram matrix contain a lot of specific information about what styles are and aren’t in the target image? Say the first filter is one that picks up on wavy lines. If there are lots of wavy lines throughout the target image, the dot product of it times itself (top left of the gram matrix) will then be very high. (And consequently, the noisy generated image will move to have more waves). Similarly, if the next filter picks up on orange, but our target style isn’t orange at all, the 2nd element on the diagonal will be near zero, and the generated image will learn not to use orange. Since we’re looking at the output of a ReLU activation, we’ll get the highest values if that feature is common throughout the target image, and low values if it is usually absent. (We’ll never have two large negative numbers multiplying to create a high positive addition to our sum).
The off diagonal values are trickier to explain, but not crazy – we might find say that wavy lines are usually blue rather than white, or some other combination like that. (And it seems plausible that these values will be a fair amount lower than the matrix diagonal, so the diagonal might be the most important factor in driving the generated style).
Hmmm… that sounds like a pretty good explanation to me, although it’s been a long time since I actually thought about this! One interesting question then would be - what if you only used the diagonal as your loss function (i.e. the correlation, I guess)? Maybe worth experimenting?
Yes that was my thought as well – I’m planning to try experimenting with that next! Seems like it should be pretty straightforward to switch - I’ll report back if it works at all…
Yes, it does just work well using only the diagonals. I think the diagonal-only version loses a bit of the style pairing info (arguably my blue sky is a bit choppier looking than in the full-matrix version, presumably since it lost the info that blue & smooth should correlate), but the output is very similar to just using the whole gram matrix. I’ll try to play around more tomorrow & post some good pictures.