Implement LinkNet(at here).
trainer.py, test.py and process_camvid.py still quite messy.
train with 800 epoch, 368 images, rmsprob, start from learning rate 0.0005, training size is 480 x 320, average accuracy on test set(333 images) reach 0.891675326947, test with the same way as lesson 14((pred == label).mean()). Before I test, I convert all of the color do not exist in the 11 labels as (0, 0, 0).
Here are examples segmented by LinkNet, I forgot to include color of sidewalk, so following results I show only train with 11 labels(Void, Sky, Building, Pole, Road, Tree, SignSymbol, Fence, Car, Pedestrian, Bicyclist).
real labels



predict labels



I guess my implementation is correct or very close to correct answer.
Loss graph
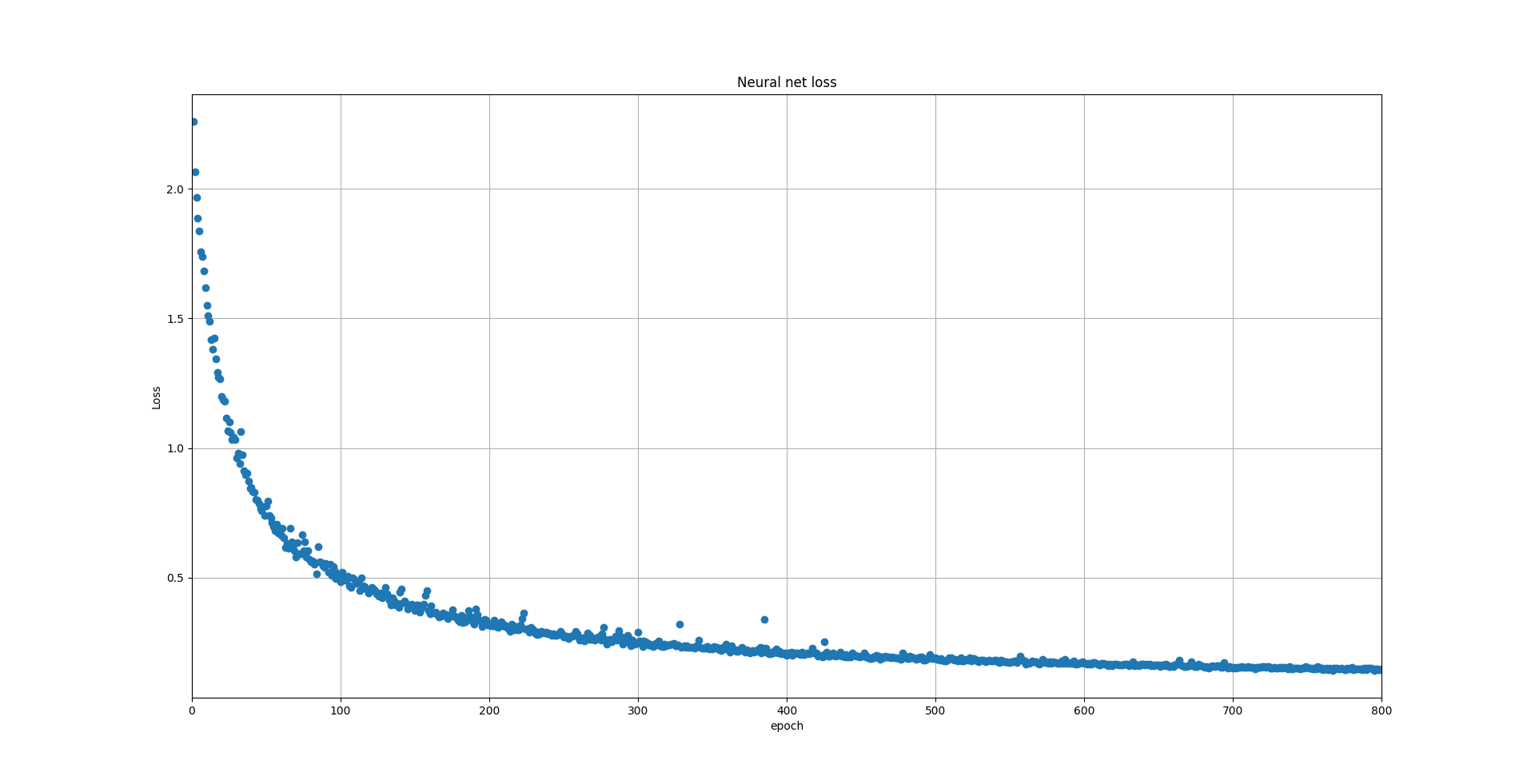
I will do more experiences on this network, like Adam vs RMSprob vs SGD, effect of training size(the bigger the better?) and write it down on my blog.
After that I intent to follow the advice of @machinethink. Do anyone interesting on how to develop a mobile app with the helps of opencv dnn module and Qt5?