I have a question about using pre-trained models for object detection and I hope you can help me getting this right
I have looked into the pascal/pascal-multi notebooks of the 2018 course and there the resnet model was used and then trained on the pascal dataset to do the multi object detection task. For the resnet model, I assume this one was a pre-trained model on ImageNet (?).
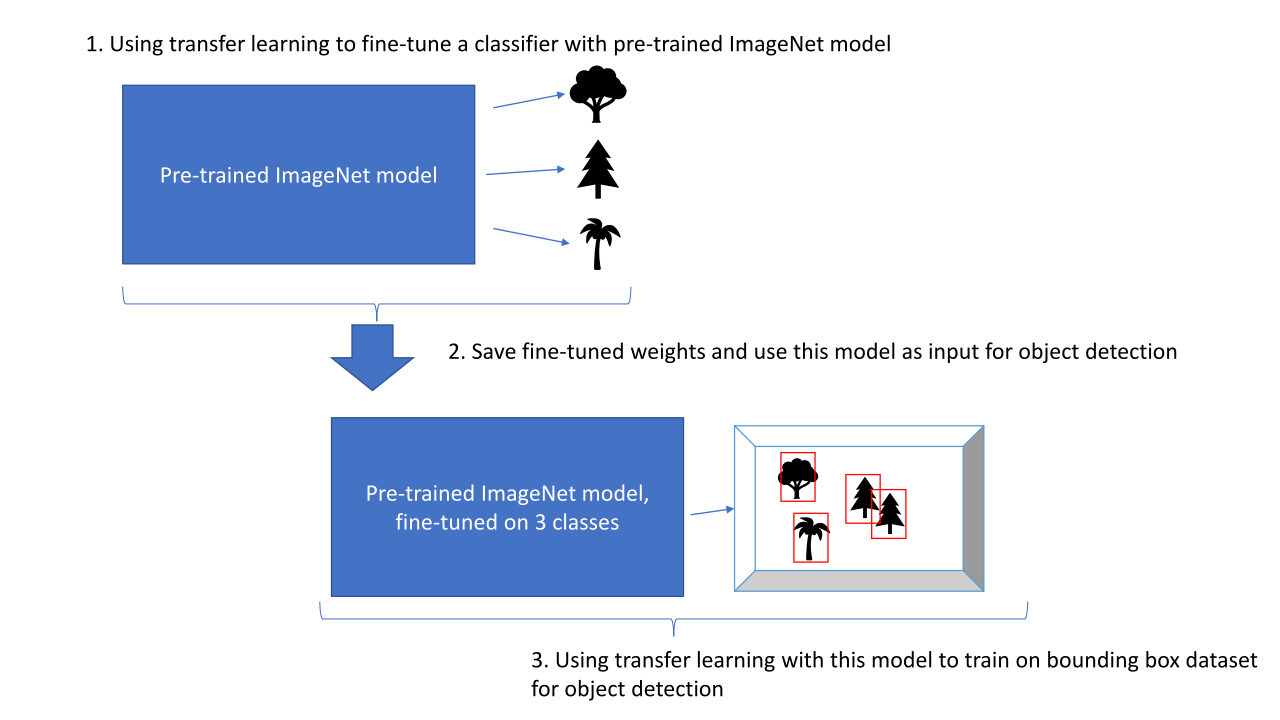
If so, the pre-trained model was actually trained to do a classification task for one object in an image and was then used with transfer learning to do the multi detection task. Am I getting this right?
So let’s say we have a dataset of labeled images for the classification of 5 classes and use a model for training that was pre-trained on ImageNet. Then (after optimizing) this model is pretty good at classifying those 5 classes. We then have another dataset of images containing these objects and the bounding boxes for those 5 classes.
My question now is: when we save the trained weights from the classification model and use this trained and optimized model as the new pre-trained model for the multi-object detection task, is this possible (and somehow useful for a higher accuracy)? Or am I missing something here?
The idea is:
I have two datasets: one for image classification with 5 classes (every image contains only one object). The images of the other dataset contain multiple objects of those 5 classes and there are bounding boxes for each object.
Both datasets are not that big (around 1000 images).
From what I have read, normally you would do transfer learning for object detection with bounding boxes with a model pre-trained on ImageNet (therefore trained for classifying) as input.
Could the accuracy be increased by
first fine-tuning a classifier to the regarding classes with the pre-trained ImageNet model
then saving this model
using this saved model for training the multi object detector model for the same object classes?
Is my question understandable?
Any suggestions, if this question is stupid or worth experimenting? Or has something similar to this already been published in some work?
If you have a backbone classifier on the object detection model, you certainly could! So long as there’s places to transfer I don’t see why not. And it should absolutely help. I haven’t worked with object detection outside of YOLOV3 (not using our library) but in theory I can’t see it not doing anything




 Or has something similar to this already been published in some work?
Or has something similar to this already been published in some work?