This my first post and I come with a question that might seem dumb to you but there is something I really don’t understand regarding CNN feature visualization.
You load a pre-trained model and freeze all its weights.
You create a random image.
You feed it into the network and compute a loss that is actually minus the mean value of the feature map corresponding to the filter you want to visualize. So the more the filter activation is high, the smaller is the loss.
You update the image thanks to this loss.
Let’s take a simple example. Here are the filter we are interested in and a random image.
If we compute the feature map, we get a single element feature map:
We see that to make the mean of the feature map the higher possible, we just have to choose the good signs for a, b, c and d and then go to infinity.
And this is actually the case if you choose a bigger image, you will just have to find the right signs and the input image will never converge.
I know there is something wrong in my reasoning as I guess this way of doing works, can you tell where is the issue ?
Your argument looks good to me, but I’ve been wrong a couple of times before .
Your logic says that the mean activation of a convolution is a linear combination of the input pixel values. Therefore, the maximum activation will be found by pushing pixels to their extremes, according to their coefficients.
If you will take a suggestion, this conclusion is easy to verify numerically. Jeremy made an Excel spreadsheet that calculates a convolution. Try pushing a few pixels to their limits to see what happens to the filter mean. You may discover an error in your proof. Or your idea may be an actual truth about convolutions, certainly one I have never thought of and one that is very interesting. Thanks!
If it is true, the problem in your reasoning about CNN visualization must lie “upstream”. Of course, once the activations pass through a non-linear activation function or a pooling layer, the mean activation is no longer a simple function to calculate and maximize. Perhaps this is the issue - in a CNN, deeper convolutional outputs have already passed through many non-linearities.
For a filter in the first level (operating directly on the input pixels) this is right.
For a fixed set of convolution coefficients, the feature-map-mean is a linear function of the input pixels. As such, every input pixel has exactly one coefficient. If that coefficient is not zero, you can push the map-mean to infinity by pushing the input pixel to infinity (with regard to the sign of the coefficient).
However, I don’t see why this is a problem. We’re not looking for convergence of the optimization problem. If you push each pixel in the right direction (negative or positive infinity) then you’ll start seeing the desired picture. Pushing the pixels further towards the optimal solution (by running more iterations of the optimizer) won’t change that picture.
In the article you linked, the optimization is aborted after a fixed number of iterations, so that’s why the problem probably doesn’t occur. If you plan to do this for longer then yes, some sort of clipping/normalization will be necessary.
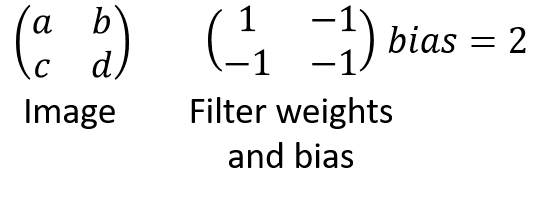
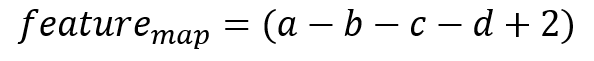
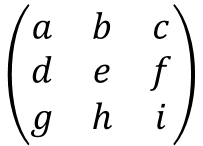
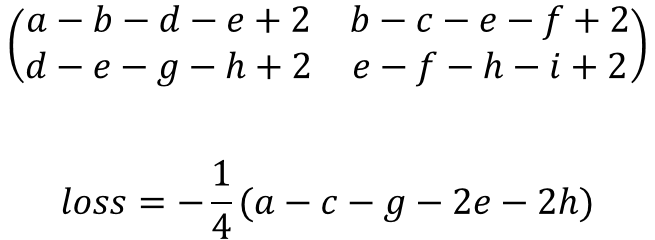
 .
.