I have a curious question about the default learning rate configuration of fit_one_cycle. I understand that the default max_lr is 0.003, and a value for the bottom bound learning rate will be chosen automatically in this case. Is the learning rate then applied evenly to all layers, or is it weighted according to the layer depth? If not, does this imply that discriminative learning rate is always applied to all FastAI models by default?
Also, is the method of learner.opt a valid way for prying in to peek at the different layer’s learning rate?
Differential learning rates are applied when we have multiple layer groups, which is usually in a transfer-learning type application. So while a tabular model can still use fit-one-cycle and it will work, the transfer-learning differential learning rates will not be applied. The cyclical cycle will be, but not the differential. This is due to those models being all ‘one group’ as no transfer learning occurs here. Whereas we have our ResNets for instance, where we separate them into two groups, the body and the head, which is the last few layers. Here we do apply it as we do not want to train the entire thing, just the top.
Just for clarification, so for the default model create out of the box with learner = cnn_learner(data, model.resnet50, metrics) will have discriminative learning rate applied to it, correct?
Correct. If we look at the source code, cnn_learner does a split() along with a freeze() if we are using a pretrained model, both combined allow for our transfer learning discriminative learning rate application (else it’s just discriminative)
I see, hmm I understand the point you are making on how the split() and freeze() is indicative of transfer learning, but I don’t see how it directly contributes to the different inter-layer learning rates.
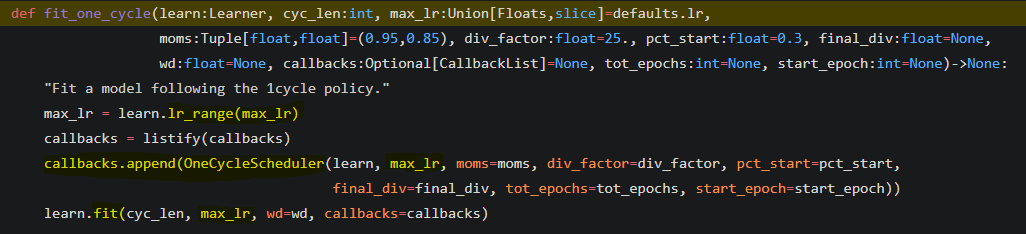
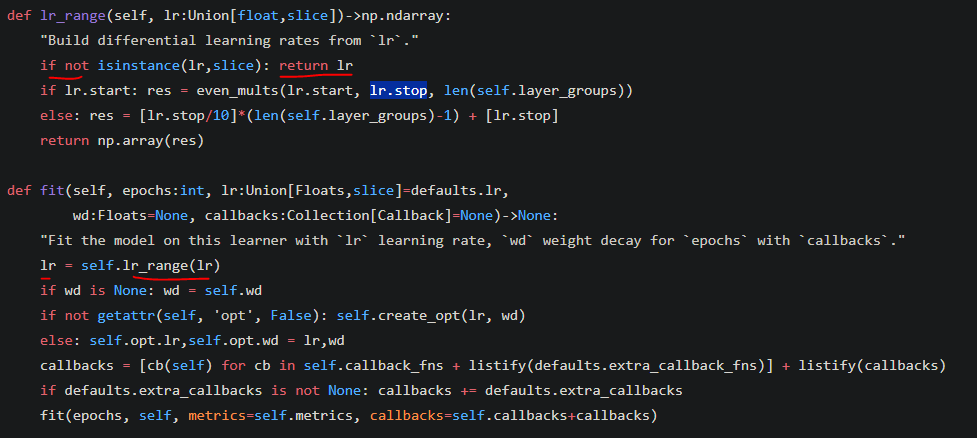
I did some digging in the source code and it seems to be from the following. Please correct me if my thoughts/understanding are mistaken :slight_smile .
(Mind the non-matching highlight and underline below)
It seems that for type slices input to lr_range, the code will return a range of learning rates and hence the discriminateive learning. On the other hand, it only returns a singular learning rate to be applied across all layers if the input to lr_range is of type float instead.
This means that if I wish to train with a uniform learning rate, I should pass a float to max_lr of fit_one_cycle, would that be correct?
You are exactly correct. That is why in lesson 1 and 2 we pass in a max_lr=slice() wheras in lesson 4 with tabular we only pass in a single float. Slice will do the differential, a singular will do all one learning rate.
If we have some model that we split into 7 different groups (for some task) we can then pass in 7 different floats into our slice to do the differential learning rates