For a text_classification_learner is it the case that just the final hidden state (of the encoder) is passed to the classification (linear) layer to make predictions? For example if we were doing sentiment analysis (with a trained model) on a sentence of length 10 would the classification block of the text_classification_learner only operate on the final hidden state output (after processing word 10) of the encoder. I think this is the way it works, but I just wanted to make sure. I just saw some material online (Stanford NLP class) that showed all the hidden states being combined before passing to the classification layer. It is probably a design decision, but I wanted to verify how fast.ai does it.
Here is the slide which prompted my question.
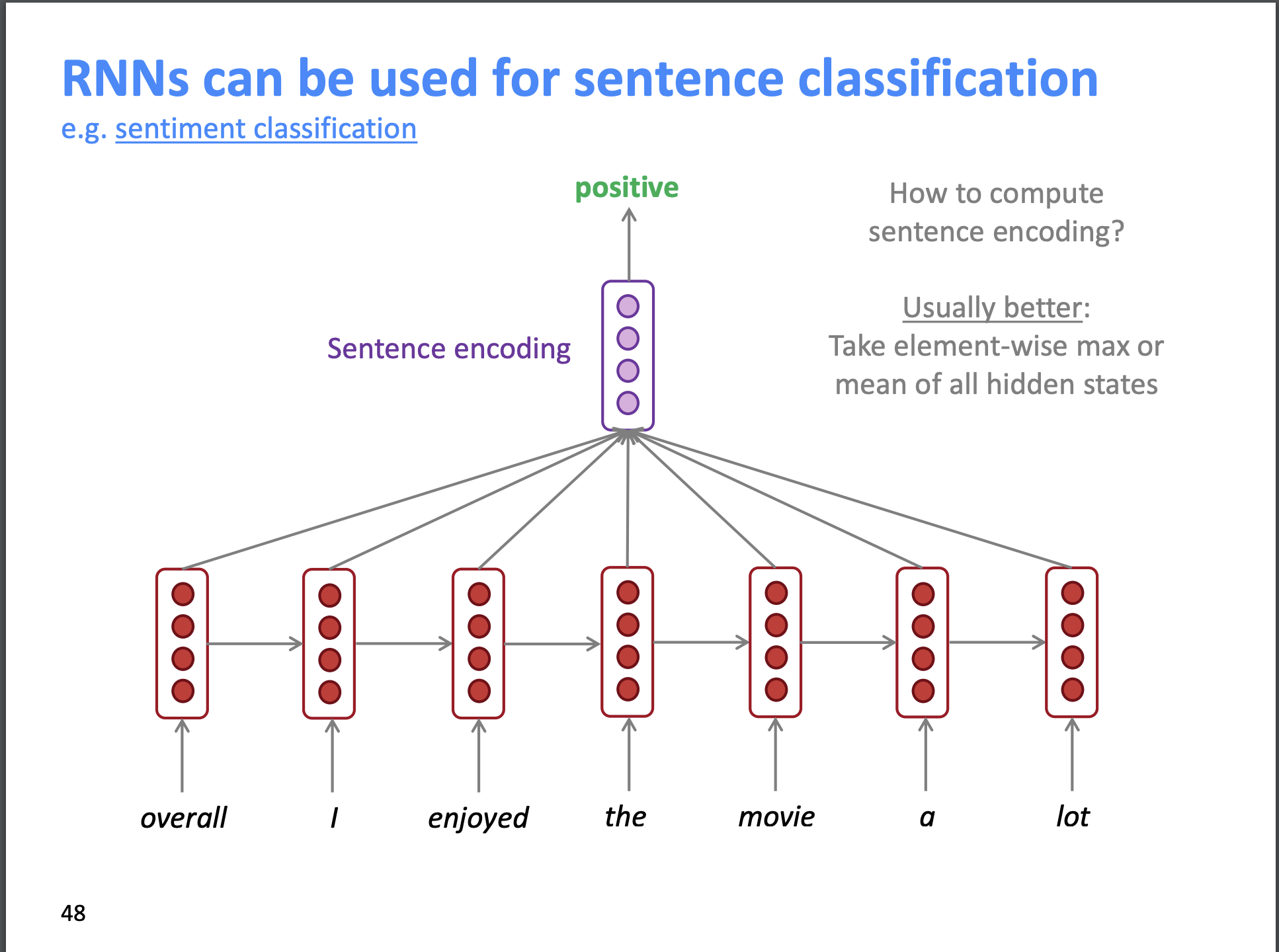
Thanks,