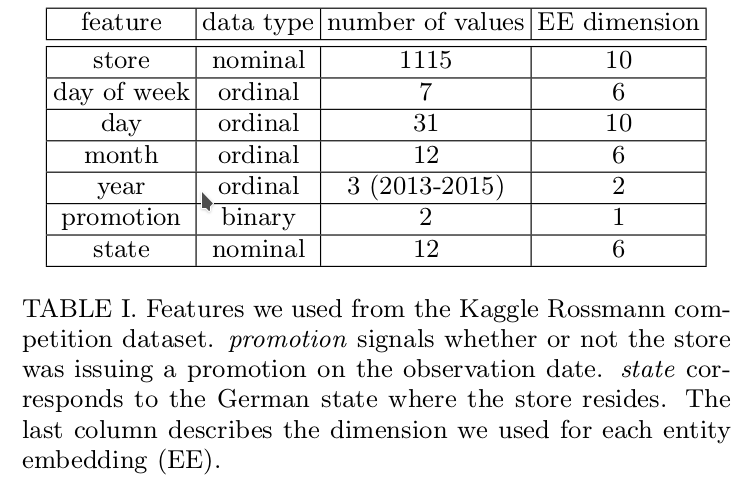
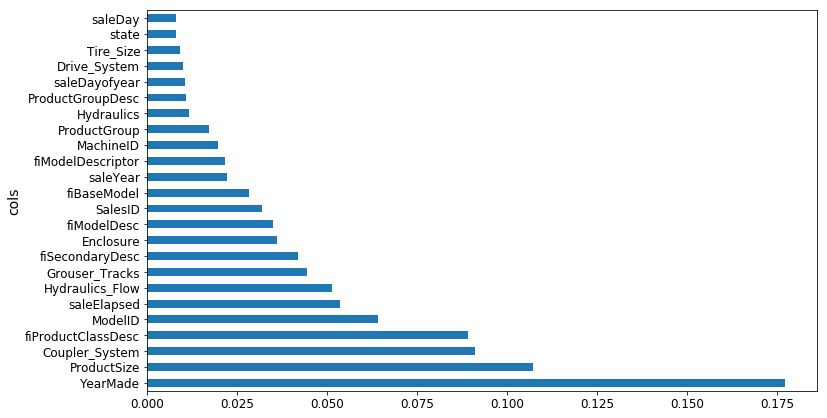
I’ve attached a table from the 3rd place winner’s paper which highlights the features they say they used for the competition. They mention that while they used other data as well, they only concentrate on these for the paper. They don’t actually talk about features such as CompetitionOpenSinceYear, SchoolHoliday_bw. I’m curious whether those are something that Jermey did as extra (which is great!). I’m curious as to why the features returned by add_datepart are not utilized at all. Furthermore, a bunch of continuous features are not used as well. Here is a list difference of the features:
cols={'elapsed', 'is_month_start', 'week', 'file_de', 'is_quarter_start', 'min_temperaturec', 'competitionopensinceyear', 'competitionopensince', 'customers', 'day', 'trend_de', 'promo2days', 'year', 'precipitationmm', 'is_month_end_de', 'afterpromo', 'state', 'promo2since', 'promo_fw', 'is_month_end', 'max_visibilitykm', 'date', 'schoolholiday_fw', 'mean_sea_level_pressurehpa', 'promo2', 'week_de', 'winddirdegrees', 'month_de', 'meandew_pointc', 'open', 'mean_humidity', 'cloudcover', 'is_year_start', 'stateholiday', 'min_humidity', 'max_gust_speedkm_h', 'competitiondaysopen', 'stateholiday_fw', 'competitionopensincemonth', 'beforepromo', 'promo', 'is_quarter_end', 'statename', 'file', 'storetype', 'is_year_end_de', 'schoolholiday', 'dayofyear_de', 'competitionmonthsopen', 'afterschoolholiday', 'schoolholiday_bw', 'store', 'month', 'index', 'afterstateholiday', 'beforeschoolholiday', 'is_year_end', 'mean_wind_speedkm_h', 'promo_bw', 'promo2weeks', 'trend', 'dayofweek_de', 'assortment', 'state_de', 'min_visibilitykm', 'min_dewpointc', 'mean_visibilitykm', 'promo2sinceweek', 'dayofweek', 'dayofyear', 'elapsed_de', 'date_de', 'competitiondistance', 'is_quarter_start_de', 'is_month_start_de', 'dew_pointc', 'promo2sinceyear', 'mean_temperaturec', 'is_quarter_end_de', 'is_year_start_de', 'events', 'max_humidity', 'promointerval', 'max_wind_speedkm_h', 'day_de', 'stateholiday_bw', 'max_sea_level_pressurehpa', 'beforestateholiday', 'min_sea_level_pressurehpa', 'max_temperaturec'}
used={'storetype', 'schoolholiday_fw', 'schoolholiday', 'dayofweek', 'week', 'competitionmonthsopen', 'min_temperaturec', 'schoolholiday_bw', 'store', 'competitiondistance', 'mean_humidity', 'competitionopensinceyear', 'cloudcover', 'month', 'day', 'stateholiday', 'promo2sinceyear', 'afterstateholiday', 'mean_temperaturec', 'min_humidity', 'trend_de', 'mean_wind_speedkm_h', 'year', 'promo_bw', 'promo2weeks', 'trend', 'events', 'max_humidity', 'stateholiday_fw', 'promointerval', 'max_wind_speedkm_h', 'stateholiday_bw', 'promo', 'assortment', 'beforestateholiday', 'state', 'promo_fw', 'max_temperaturec'}
cols-used
{'date', 'is_year_end_de', 'mean_visibilitykm', 'promo2sinceweek', 'dayofyear_de', 'mean_sea_level_pressurehpa', 'promo2', 'elapsed', 'week_de', 'is_month_start', 'winddirdegrees', 'dayofyear', 'elapsed_de', 'afterschoolholiday', 'file_de', 'month_de', 'is_quarter_start', 'date_de', 'meandew_pointc', 'open', 'is_quarter_start_de', 'competitionopensince', 'is_year_start', 'is_month_start_de', 'customers', 'index', 'dew_pointc', 'beforeschoolholiday', 'promo2days', 'is_year_end', 'precipitationmm', 'is_quarter_end_de', 'max_gust_speedkm_h', 'is_year_start_de', 'competitiondaysopen', 'is_month_end_de', 'competitionopensincemonth', 'beforepromo', 'afterpromo', 'day_de', 'dayofweek_de', 'max_sea_level_pressurehpa', 'state_de', 'min_sea_level_pressurehpa', 'is_quarter_end', 'promo2since', 'is_month_end', 'statename', 'min_visibilitykm', 'min_dewpointc', 'max_visibilitykm', 'file'}