Does a batch size of 64 mean that we divide the whole training data into 64 pieces (batches) and feed one batch at a time into the neural net, calculate the gradient and then change the weights accordingly? Or does it mean that one batch consists of 64 training examples?
Isn’t increasing the batch size to lets say 128 actually halving the batch size, because now the individual batches are just halve as big as before (now you divide the whole training set in twice as many batches).
Second question: How does the batch size affect the ability of the neural net to converge?
Your second view is correct. It means each batch consists of 64 training examples. Increasing the batch size to 128 does indeed make a bigger batch.
The second question is more difficult. The larger the batch size the more memory you need. The smaller the batch size the more updates you need. You need to find the best compromise. Using batches improves generalisation error.
OK, now I understand your confusion. I was referring to mini-batches for training neural networks.
The NLP example is different; the key statement from the notebook is:
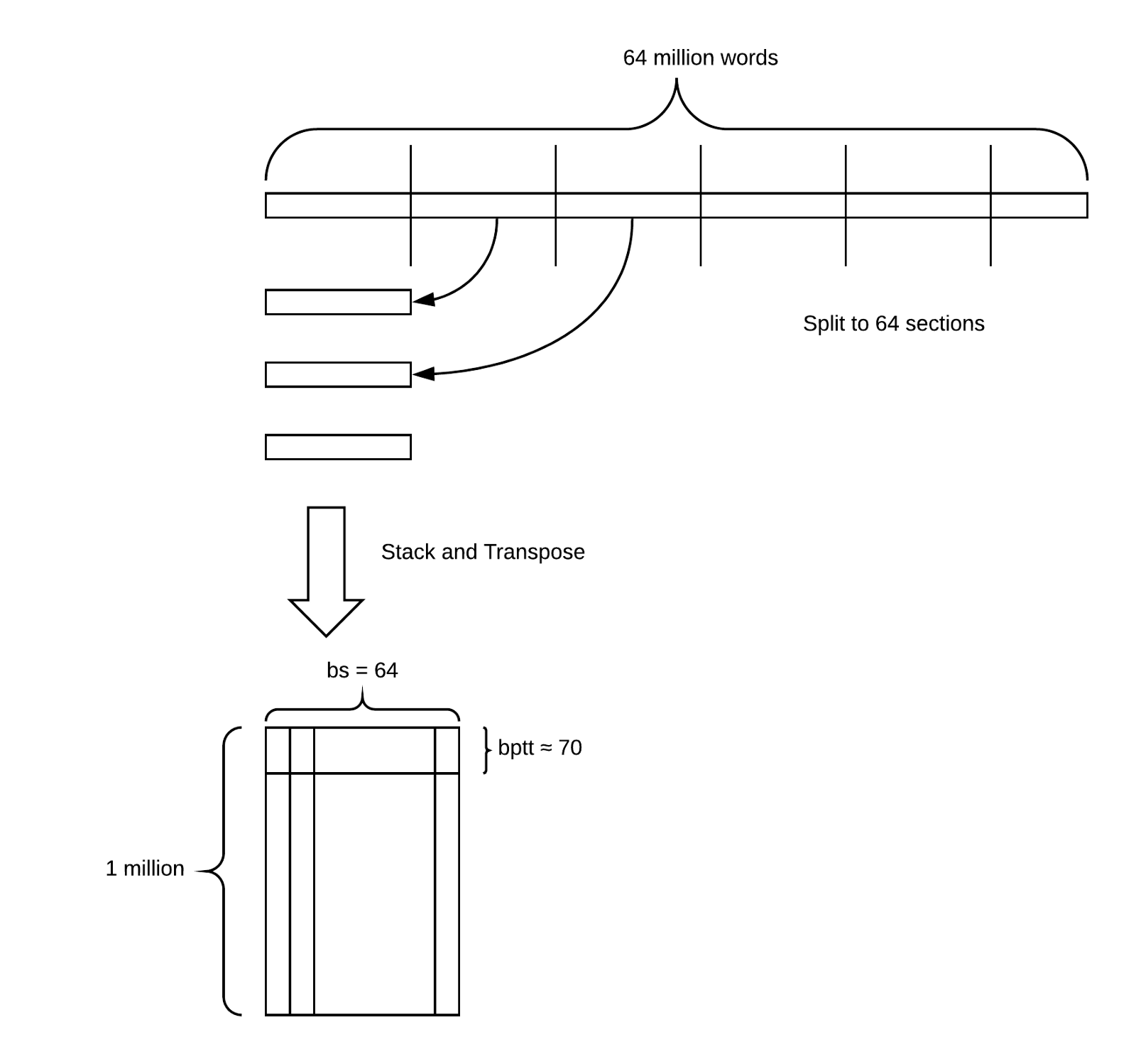
“Our LanguageModelData object will create batches with 64 columns (that’s our batch size), and varying sequence lengths of around 80 tokens (that’s our bptt parameter - backprop through time ).”
Here there are batches of 64 columns x around 80 rows. The whole matrix of IMDB reviews is indeed divided into 64 parts - these become the columns containing the reviews in order in the bottom matrix. The batches come from this matrix, each of size bs width x bptt height (bptt varies).
Thank you for your explanation. I was also refering to the actual mini batches for stochastic gradient but the example of the Imdb problem was a bit confusing because there bs is defined differently.
I understood mini batch is bptt*batch_size and Jeremy says, bptt is approximately 80 .that is it varies from mini batch to mini batch.
I am curious to know, how do you feed each mini batch to lstm?
According to my understanding, during 1st mini batch , if bptt =78, then , unrolled lstm will have 78 lstm units .
Now during 2nd mini batch if bptt =70, then unrolled lstm will have 70 units of lstm ? Is this correct?
Bptt is replacenent of seq length (rnn)?
Is seq_len and bptt same ? By seq_len , I mean no of lstm units (unrolled) in a layer.