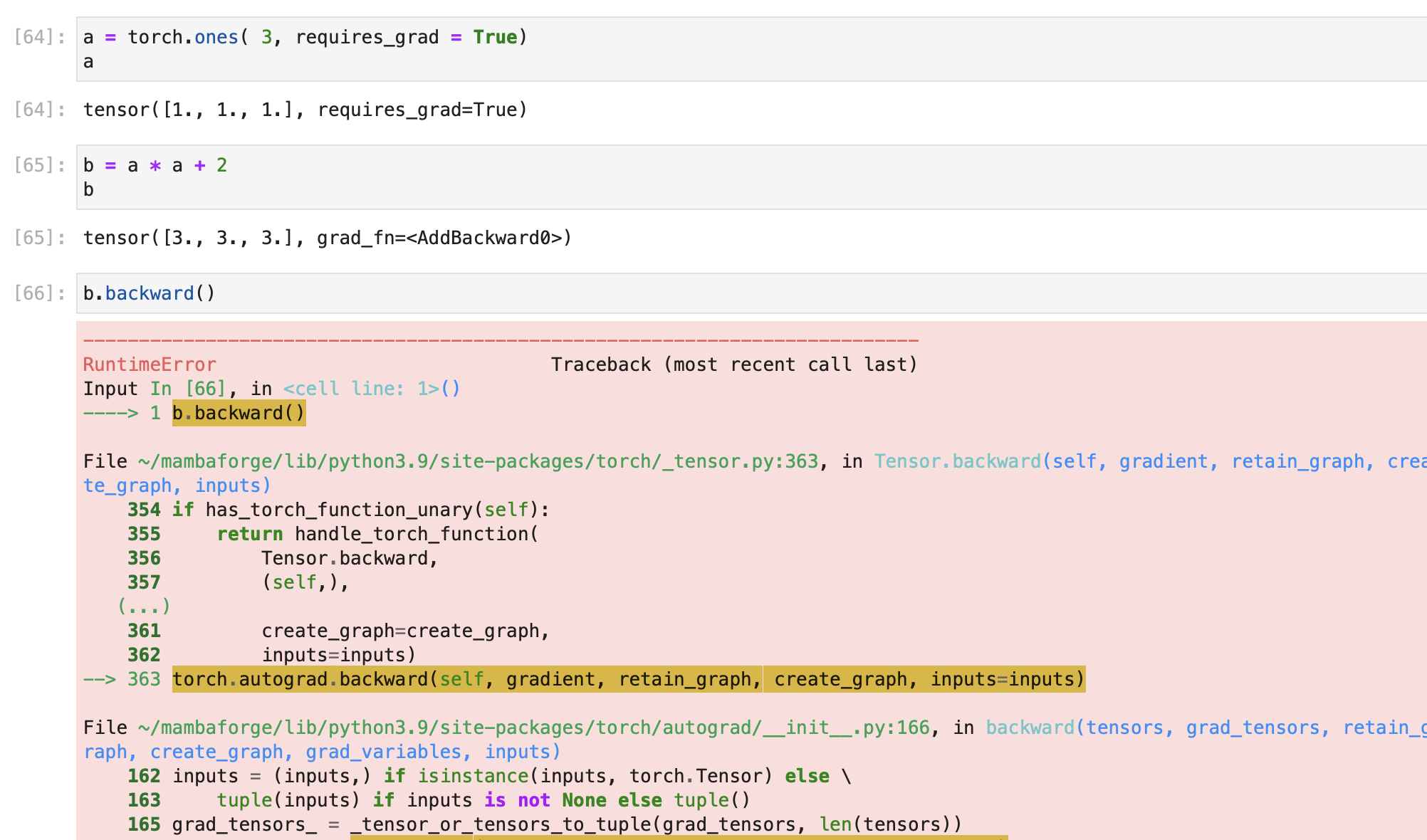
following lesson 5 I experimented with gradient. For this I created tensor a of rank 1 with 3 times 1.
Next I defined b = a * a + 2, knowing that db/da = 2a
Hence calling b.backward() should result in: tensor( [2, 2, 2])
Instead I get: “RuntimeError: grad can be implicitly created only for scalar outputs”
Can somebody explain why I get this error message?
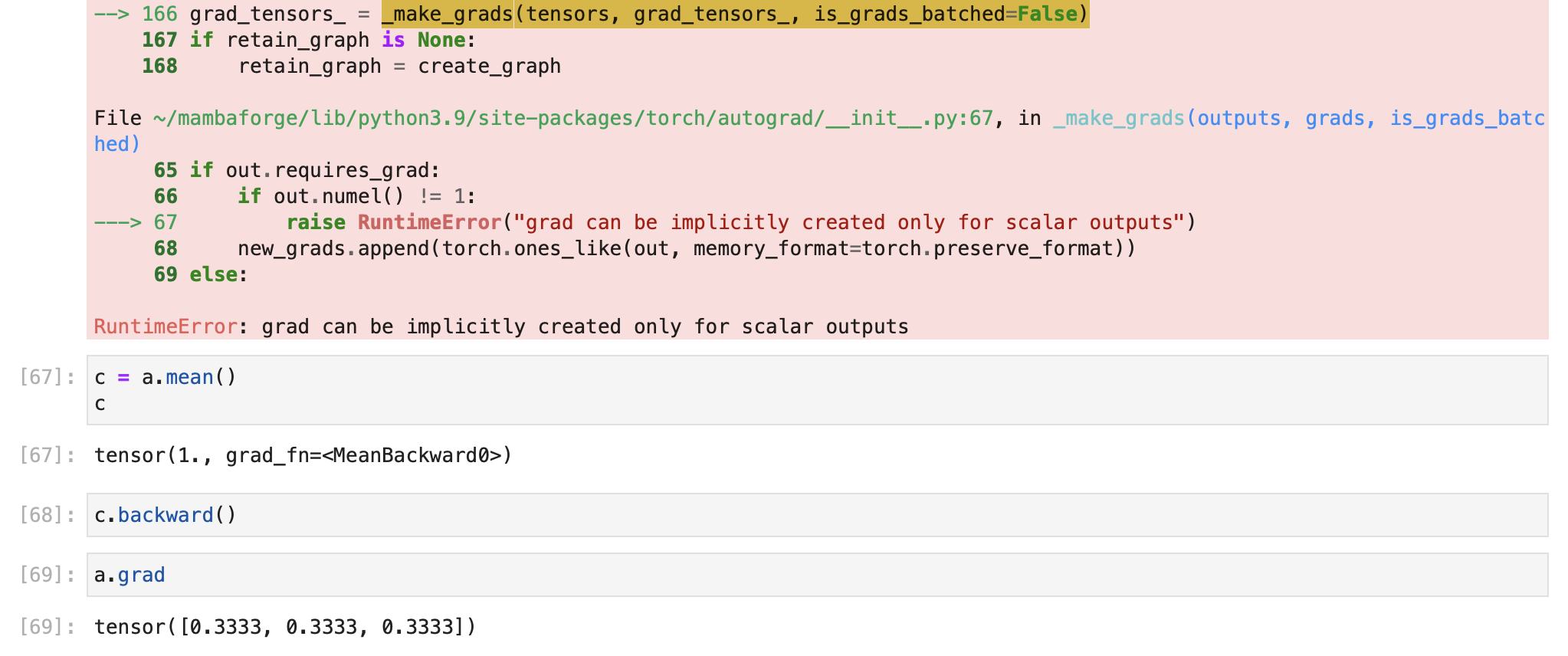
Next I tried:
c = a.mean()
c.backward()
This gives me: tensor([0.3333, 0.3333, 0.3333]), which is the mean but not the gradient.
What am I missing to understand this?
When x.backward() is called, x must be a scalar to perform the backward pass. The rationale behind that is as follows. Suppose you are training a neural network with two losses - loss1 and loss2 - that are contained within a single tensor loss = torch.tensor([loss1, loss2]). How would the chain rule behave in this case? Should the gradient of each layer be the gradient of loss1 with respect to it plus the gradient of loss2 with respect to it? Or perhaps it should be the average of the gradients of loss1 and loss2 with respect to it? Etc. Therefore, PyTorch requires the user to specify their method of choice by passing a tensor to the gradient argument of x.backward() that contains the weights assigned to the values of x if it is a tensor, e.g., loss.backward(torch.tensor([1.0, 1.0])) or loss.backward(torch.tensor([0.5, 0.5])) for summing or averaging the gradients of loss1 and loss2 respectively. Alternatively, one can first take the weighted average of the two losses and perform the backward pass thereafter, for instance, (loss1+loss2).backward() or (0.5*loss1 + 0.5*loss2).backward(). Here, both methods are equivalent.
In your case, the gradients need to be added, that is, b.sum().backward() or b.backward(torch.tensor([1.0, 1.0])).
The result is a tensor of [2, 2, 2]; which is what I expected
But I have to say I am still struggling with this, because the chain rule has no weights.
Think of it like this - you have grad1, grad2, and grad3 as the gradients of the first, second, and third element of a respectively (this terminology is incorrect since gradients are vectors, and grad1, grad2, and grad3 are (partial) derivatives, but that is irrelevant here.) After performing the backward pass, grad1 is multiplied by v[0], grad2 by v[1], and grad3 by v[2]. In the version of calculus you are most likely familiar with, where you do, for instance,
you can consider the values of v to be implicitly 1. PyTorch can by default set the gradient argument to a tensor of ones for simplicity, but there is an old GitHub issue requesting such a feature that was rejected.
thanks Bob.
For now I will continue my AI journey keeping the gradient argument in mind; there is much to learn.
I have the feeling that PyTorch was designed with the backward pass of back propagation in mind.