After playing around with Jeremy’s fast imagenet process notebook, I wanted to start a thread for all of us to discuss parallel processing in python. Specifically, the benefits/drawbacks, applications for deep learning, and to share anecdotal performance benchmarks and ideas for how we can improve our model training times.
After the lecture, I read up on Python’s new concurrent.futures library and wrote some test code to see if I could replicate the benefits. To start, here are some very rough notes on the differences. I also put together a small jupyter notebook to verify these ideas in practice.
What is parallel processing?
Basically doing two things at the same time, by either running code simultaneously on different CPUs, or running code on the same CPU and achieving speedups by taking advantage of “wasted” CPU cycles while your program is waiting for external resources–IO, API calls.
Serial Programming
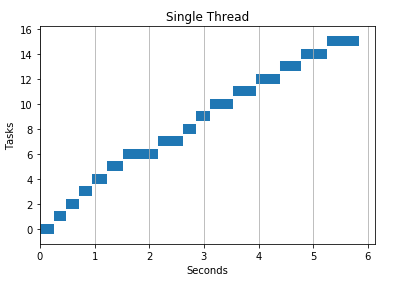
Parallel Programming
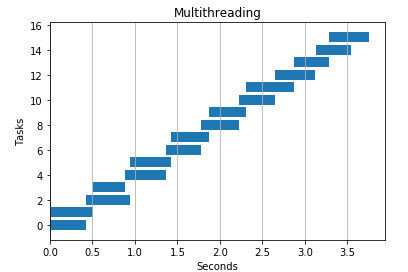
In this example we use two threads to achieve speedups over normal serial programming.
Processes vs Threads
A process is an instance of program (e.g. Jupyter notebook, Google Chrome, Python interpreter). Processes spawn threads (sub-processes) to handle subtasks like reading keystrokes, loading HTML pages, saving files. Threads live inside processes and share the same memory space (they can read and write to the same variables).
Ex: Microsoft Word
When you open Word, you create a process (an instance of the program). When you start typing, the process spawns a number of threads: one to read keystrokes, another to display text on the screen, a thread to autosave your file, and yet another to highlight spelling mistakes. By spawning multiple threads, Microsoft takes advantage of “wasted CPU time” (waiting for your keystrokes or waiting for a file to save) to provide a smoother user interface and make you more productive.
Process
- Created by the operating system to run applications and programs
- Processes can have multiple threads
- Processes have more overhead than threads as opening/closing processes takes more time
- Sharing information between processes is slower than sharing between threads as processes do not share memory space. In python they share information by pickling data structures like arrays which requires IO time.
- Two processes can execute code simultaneously in the same python program
Thread
- Threads are like mini-processes
- They exist in shared memory space and can easily access the same variables
- Two threads cannot execute code simultaneously in the same python program (with exceptions)
Python’s GIL problem
- CPython and GIL prevent two threads from executing simultaneously in the same python program
- Other languages do not have this problem and are able to run multiple threads simultaneously on multiple cores/CPUs
- Libraries like Numpy work around this limitation by running external code in C
CPU vs Core
- The difference is slightly confusing to me (please correct me), but a CPU, also known as a “processor” manages the fundamental computation work that allow computers to run programs.
- A CPU can have multiple cores, which allow the CPU to execute code simultaneously.
- With a single core, there is no speedup for CPU-intensive tasks (loops, arithmetic), but the ability to launch multiple threads/processes allows applications to “seem to do things simultaneously” which is important for a buttery user experience and does achieve speedups
- With only 1 CPU, only one instruction can be run at a time, so the OS switches back and forth between threads/processes executing each a little at a time.
When to use threads vs processes?
- Multiprocessing - can speed up Python operations that are CPU intensive b/c they benefit from multiple cores/CPUs and avoid the GIL problem
- Multithreading - no benefit in python for CPU intensive tasks b/c of GIL problem (this problem is unique to CPython)
- Multithreading is often better than multiprocessing at IO or other tasks that rely on external systems because the threads can combine their work more efficiently (they exist in the same memory space). Multiprocessing needs to pickle the results and combine them at the end of the work
Here’s a good SO post on the differences.
Numpy Operations
- For certain operations, (dot product), Numpy works around python’s GIL and can execute code in parallel on multiple CPUs.
- Dot product uses parallel processing by default. You don’t need to write custom multitasking code
- Other Numpy operations like multiplication and addition, do NOT run in parallel by default, however, unlike vanilla Python code, you CAN achieve speedups with threads/processes
- Numpy works around the GIL because its python code makes calls to code in raw C
Context Switching and Overhead
- For small operations (only a few loops), I didn’t see any benefit from multitasking
- This is likely because of the overhead of launching and maintaining multiple threads/processes (OS context switching)
Some Example code
def multithreading(func, args, workers):
with ThreadPoolExecutor(max_workers=workers) as executor:
res = executor.map(func, args)
return list(res)
def multiprocessing(func, args, workers):
with ProcessPoolExecutor(max_workers=workers) as executor:
res = executor.map(func, args)
return list(res)
API calls
I found threads work better for API calls and see speedups over serial processing and multiprocessing
def download(url):
try:
resp = urlopen(url)
except Exception as e:
print ('ERROR: %s' % e)
2 threads
4 threads
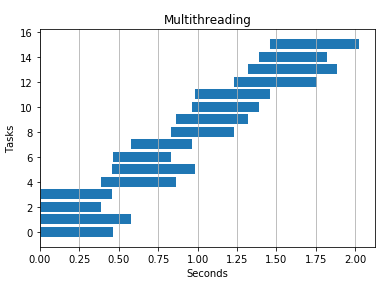
2 processes
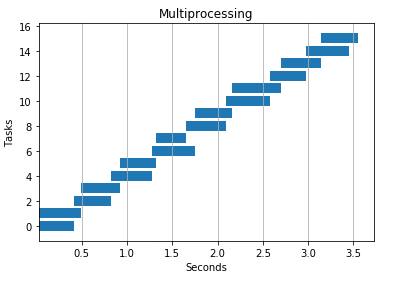
4 processes
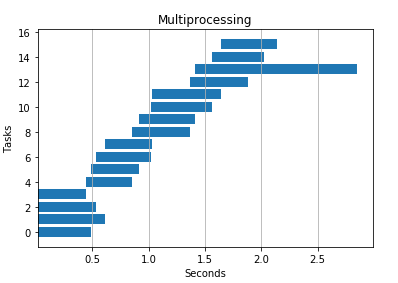
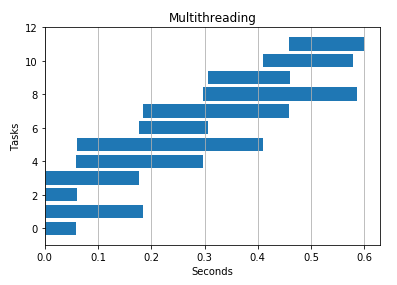
IO Heavy Task
I passed in a huge file to see how performance differed. Threads seemed to win here again, but multiprocessing also beat serial processing.
def io_heavy(text,base):
start = time.time() - base
f = open('output.txt', 'wt', encoding='utf-8')
f.write(text)
f.close()
stop = time.time() - base
return start,stop
Serial
%timeit -n 1 [io_heavy(TEXT,1) for i in range(N)]
>> 1 loop, best of 3: 1.37 s per loop
Multithreading 4 threads
Multiprocessing 4 processes
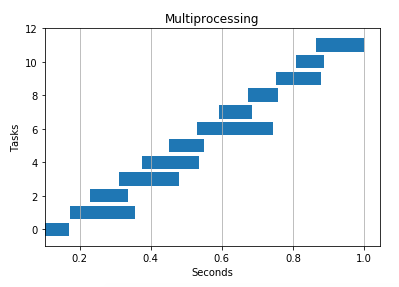
Numpy Addition
Multiple threads/processes helped here, but only to a point. If I added too many I started to see slow downs. Likely due to the overhead of launching processes/threads and context switching.
def addition(i, base):
start = time.time() - base
res = a + b
stop = time.time() - base
return start,stop
Serial
%timeit -n 1 [addition(i, time.time()) for i in range(N)]
>>1 loop, best of 3: 14.9 s per loop
2 Threads
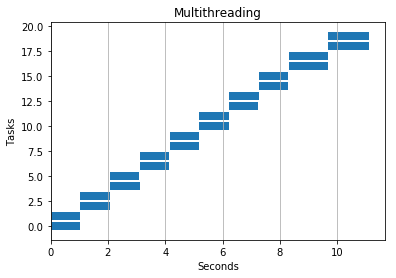
4 Threads
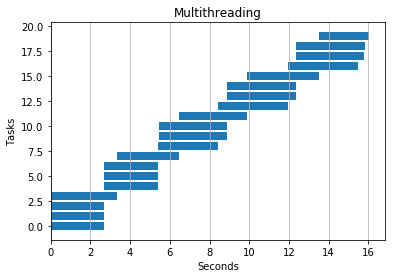
Dot Product
As expected, I saw no benefit from adding threads or processes to this code. Parallel processing works out-of-the-box.
def dot_product(i, base):
start = time.time() - base
res = np.dot(a,b)
stop = time.time() - base
return start,stop
Serial: 2.8 seconds
2 threads: 3.4 seconds
2 processes: 3.3 seconds
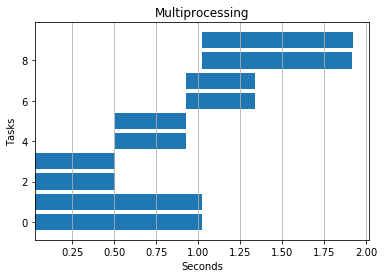
CPU Intensive
Multiprocessing won the day here as expected–multiple processes avoid python’s GIL and can execute simultaneously on different CPUs/cores.
def cpu_heavy(n,base):
start = time.time() - base
count = 0
for i in range(n):
count += i
stop = time.time() - base
return start,stop
Serial: 4.2 seconds
4 threads: 6.5 seconds
4 processes: 1.9 seconds
Here’s the notebook you can use to play around with this code.
Resources
Here are all the great articles I benefited from as I researched this topic. I’m only rehashing what’s been explained by my betters.
- \http://stackoverflow.com/questions/3044580/multiprocessing-vs-threading-python
- \http://stackoverflow.com/questions/5260068/multithreaded-blas-in-python-numpy
- \https://en.wikipedia.org/wiki/Amdahl's_law
- \http://stackoverflow.com/questions/8463741/how-linux-handles-threads-and-process-scheduling
- \http://stackoverflow.com/questions/1718465/optimal-number-of-threads-per-core/10670440#10670440
- \http://stackoverflow.com/questions/481970/how-many-threads-is-too-many
- \https://nathangrigg.com/2015/04/python-threading-vs-processes
 I read through it, and it all looks right to me.
I read through it, and it all looks right to me.
 I just use one process and dream while it works.
I just use one process and dream while it works.