Hi,
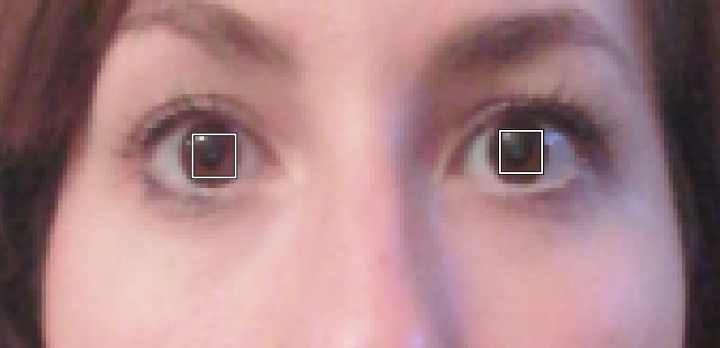
I have annotated approximately 200 images with purpose to train the model to detect pupils. Every image is annotated with two points that represent the pupils. As the dataset is small, I wanted to augment the dataset the way it was augmented for object detection. In order to correctly transform dependent variables, I have transformed the points to bounding boxes; for every pupil (x, y), I have created a bounding box with y_min = y - image_height/20, x_min = x - image_width/20, y_max = y + image_height/20, x_max = x + image_width/20
After evaluating the dataset, the bounding boxes seemed OK:
In order to train the model, I have tried to reshape the output that represents 2 bounding boxes back to 2 points:
def bb2centroids(source_tensor):
batch_size, coords_count = list(source_tensor.size())
bb_count = coords_count/4
box_coords = torch.functional.split(source_tensor, 1, dim=1)
centroid_coords = torch.cuda.FloatTensor(())
for i in range(int(bb_count)):
bb_idx = i * 4
y1 = box_coords[bb_idx]
y2 = box_coords[bb_idx + 2]
x1 = box_coords[bb_idx + 1]
x2 = box_coords[bb_idx + 3]
y = (y1 + y2)/2
x = (x1 + x2)/2
centroid_coords = torch.cat((centroid_coords, y), 1)
centroid_coords = torch.cat((centroid_coords, x), 1)
return centroid_coords
After this, I have tried to minimize the MSE, but the model accuracy was really bad.
I have also tried to use the sum of euclidean distances as a loss function but there was no improvement:
def get_centroid_distances(input, target):
centroids_input = bb2centroids(input)
centroids_target = bb2centroids(target)
batch_size, coords_count = list(centroids_input.size())
points_count = coords_count/2
losses = torch.cuda.FloatTensor(())
points_coords_input = torch.functional.split(centroids_input, 2, dim=1)
points_coords_target = torch.functional.split(centroids_target, 2, dim=1)
for i in range(int(points_count)):
loss_current = (points_coords_input[i] - points_coords_target[i])**2
loss_current = torch.sqrt(loss_current.sum(1, keepdim=True))
losses = torch.cat((losses, loss_current), 1)
return torch.mean(losses)
I will continue to work on this model and try to improve it but nevertheless any of your practical experiences that might be relevent to this challenge might help. I guess one reason for bad performance is the size of the dataset. - will annotate more images along the way. Another thing that I am wondering if it improves or reduces the model’s accuracy is transformations of the points to bounding boxes and then back to points. The only reason I did this is that in such way it was possible to take advantage of existing fast.ai function for augmentation of dependent variables. I will also try to avoid data augmentation and manually set dependent variables (y and x coordinates) to coord_y/image_height, coord_x/image_width.
Anyway, any comment or suggestion would be appreciated.
Best regards,
Niko