I’ve been working on implementing the DeepAR model from this paper:
My basic interpretation of the model is that its basically an autoencoder that “encodes” the past to “decode” and predict the future (please correct me if I’m wrong here).
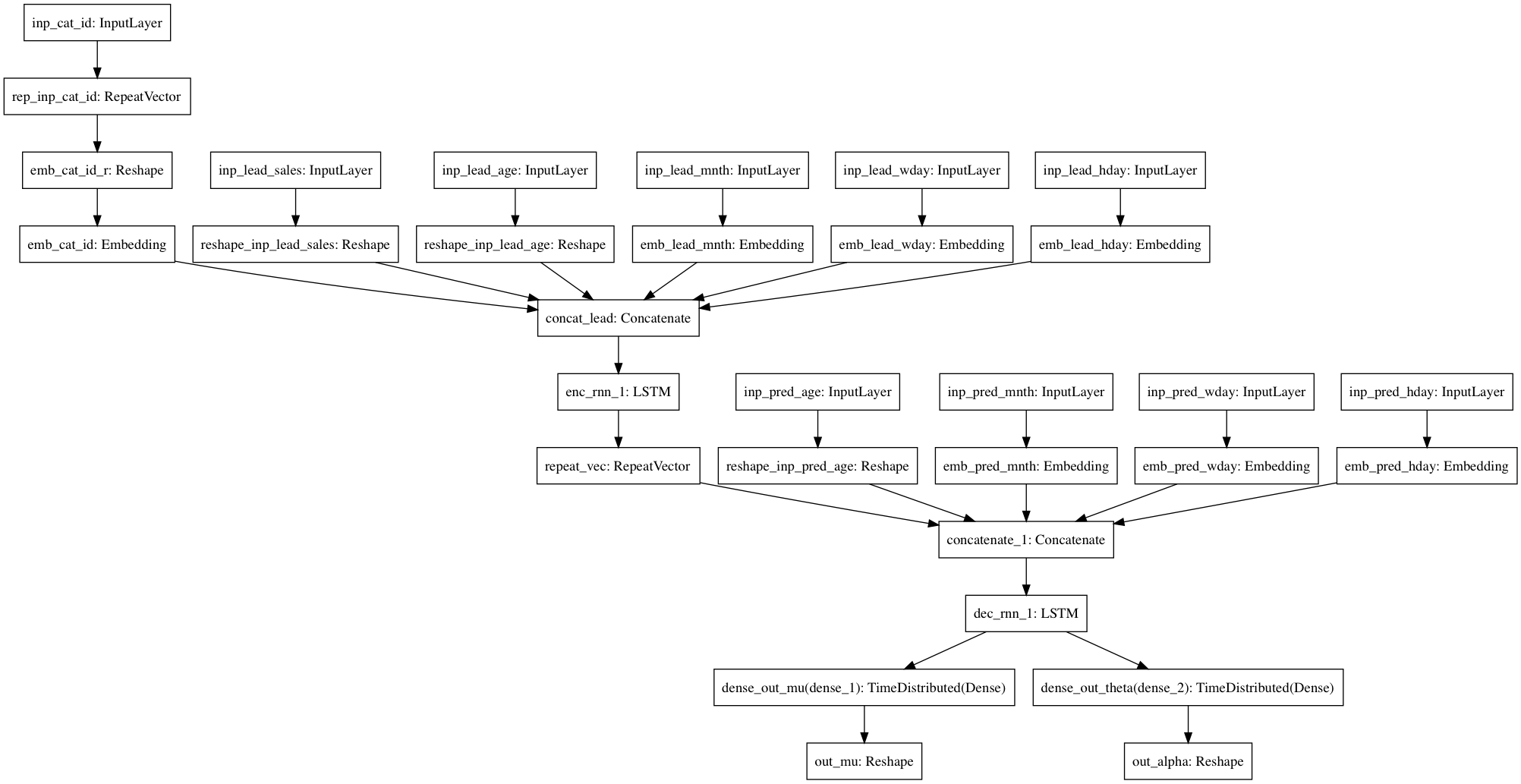
I have a working model, but was hoping for some guidance on the best practices for using embeddings. I have inputs that are and aren’t time dependent. For time dependent variables like weekday and month, I currently have 2 separate encoders, one on the encoding side and another on the decoding side (see pic of model structure below). Does that architecture make sense? That seems like its learning 2 embeddings for the same variable, which doesn’t make too much sense. Should I use one embedding layer and feed both the “leading” and “future” inputs through it? That also seems weird since the leading inputs are trying to encode, while the future inputs decode. Another thing I think I saw (maybe here or fast.ai github?) was using the inverse of the embedding? I haven’t thought through how to do that yet, but if this is best method in practice, I’m open to testing it out.
For the non time dependent inputs (i.e. item type), should I just feed that embedding into the encoder? Or should I also use an embedding on the decoder side as well? I haven’t added this part to the model yet, but my though is that I should just use that input for the encoder since the encoded vector should capture all the nuances of that category. Again, open to suggestions on this part.
At the end of the day, I could test performance on all these assumptions, but I also have a bunch of different hyperparams to test (number of layers, layer dims, etc.) so I’d like to at least start in the right direction with proper architecture.