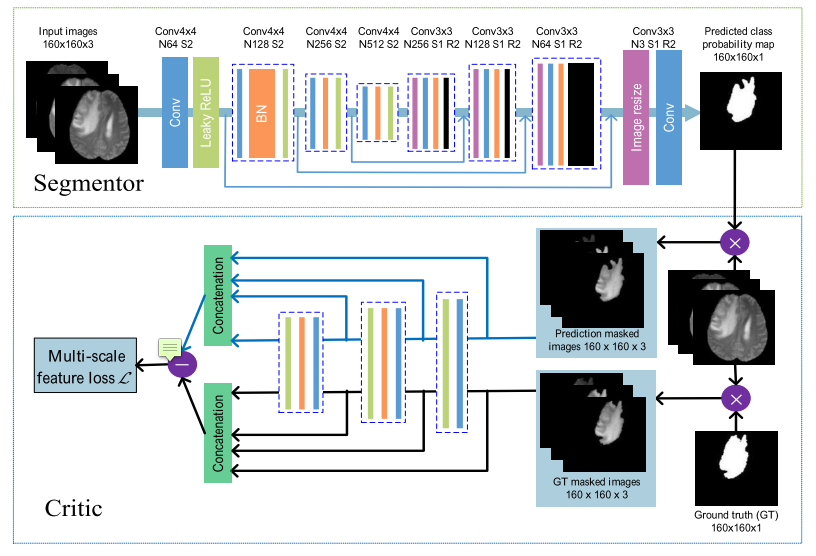
They use a (W)GAN architecture for image segmentation. The generator part (called segmentor here) uses a U-Net like architecture, while the discriminator (here called critic) employs a novel multi-scale loss (essentially MAE over feature maps on different scales).
I’d start out with something simple to get the code working (e.g. thresholded MNIST) and then move to more real-world data sets.
In the mean time I went ahead and implemented a SeGAN class including the training loop for the non-Wasserstein case.
I got it working on MNIST and am testing it on production data. Once I am satisfied with it I might post some code.
Hi iNLyze, thank you for your code for SegAN! You helped other people who are also interested in SegAN and gave them something to start with, we really appreciate your work. We have released our SegAN code here. Our original SegAN code was written in Tensorflow with a very old version of TF and the released version is reimplemented in Pytorch on a skin dataset with a different architecture (data are very similar to natural images so everyone can try it on his own tasks). The released code might not be perfect for now but I think the idea is there. Feel free to play with it and let me know if you have any questions!
Dear @YuanXue, I appreciate your new version in PyTorch. I feel a bit bad myself about not being able the code I released, as I have been goong through a diffixult stretch in my personal life. Segmentation is still something that excites me. Once things are improving I‘ll be happy to check out your version. I might take mine down then, since I wonder if it will still be needed. Keep up the good work!
No worry, you can keep your code since people are interested in it and you truly helped them with your code. Besides, I’m glad to see other people could provide some different perspectives on SegAN, and please don’t feel bad for yourself since my code is not perfect either. You’ve done very good job, hope you will feel better in your life soon!
Hi @iNLyze and @YuanXue!
First of all, I wish you a happy new year.
I came across the @YuanXue code and the @iNLyze version in Keras. This approach is really interesting and I would like to go into it. Unfortunately, because of my limited Keras and PyTorch knowledge I can not understand some aspects of the two versions like the difference between the used losses.
I hope you are still interested in developing this project and thank you for your availability
Dear @alexover, thanks for your interest. I have not worked on this project for a while, but please feel free to ask your questions here, so others can benefit from them as well.
Thank you for the reply!
My first question is about converting the Network in Keras. In the original implementation of @YuanXue loss function is made by MAE and DSC. Why in your implementation only MAE was used?
I tried to implement the original loss but didn’t work in Keras…
Thank you for your interest in SegAN. I think you can use the L1 loss either alone or combine with the dice loss, depending on performances. I hope SegAN can be a flexible and general framework and everyone can apply it to his own work.
I’m not familiar with Keras but you can experiment with the L1 loss only first. In our original TF implementation, I remember we used tf.abs and tf.reduce_mean for L1 loss.
I think mostly, because I wanted to use a fairly simple and straightforward solution before using a combination of losses. Might be a good thing to try, though.
Recently I implemented gan based framework for segmentation, something similar to the idea of segan. As far I understand, the generator loss function is L1. Because of this the output will be a regression map. But in case of unet, the output will be a classification map. In classification case, I would normally take a argmax and find the discrete values. How can I do that for the L1 loss case ? I have to calculate the metrics based on that. Any inputs here ?