OK it’s largely fixed now. I had to add inplace=True to the relu. Can’t quite run darknet_53, but I’ve added a darknet_small that’s got just 4 fewer conv layers and that fits in 16GB (just!)
BTW @sgugger I refactored quite a bit so you may want to re-run your test and ensure you get the same results. It’s looking OK in my brief tests, but I haven’t been looking at this as long as you.
I’ve run it for three epochs and it seems to be training the same way as the full version.
1 Like
Isn’t better to have the same architecture rather than the batch size to get results, similar to theirs ?
We’re trying a range of experiments to see what works best for DawnBench.
3 Likes
I was having an issue importing the fastai.darknet module: getting a ModuleNotFoundError for the line:
from .layers import *.
Changed that to:
from fastai.layers import *
and the import worked fine. I think this is because darknet.py is in /models/ and not in the main fastai library directory.
I’m not sure about submitting a PR since it looks like fastai models are defined in torch_imports.py? – so this is just a WIP state?
By the way, I’m counting the Conv layers in darknet53 … and I keep coming up with 52… but the paper says they have 53 conv layers. Importing the fastai version (@sgugger’s implementation?) – same thing.
1 Like
Yeah darknet-53 has only 52 convolutional layers (which I counted twice in their paper since it made me pause too).
I think the 53 is because they count the last Linear layer for classification. Or maybe it’s some kind of joke.
3 Likes
Hah, that’s exactly what I thought.
Has anyone here trained the fastai darknet53 on ImageNet yet? I’m refactoring a project and planning on using darknet53 as a detector.
So far I’m thinking:
- train on ImageNet to some baseline
- train on Pascal VOC to learn bounding boxes
I’m guessing we don’t have pretrained weights yet for the fastai version of this. Anything special I should know about building pretrained ImageNet weights? I figure it’s basically Part 1 stuff: train on a subset to work out any bugs, then train until the validation loss stops improving – then do it all over again on the full dataset. I’ll take a look at cyclic learning rates.
edit: so apparently ImageNet also has bounding boxes now – ah, they say it’s incomplete so far.
1 Like
I think I’m just about ready to train on the ImageNet sample before moving to the full dataset, but I wanted to share a couple things first.
Here is the notebook I’m running this in. I’m using the JHoward/SGugger fastai implementation of Darknet53.
I’m getting some strange behavior when running learn.lr_find(): the learning-rate finder is ‘prematurely’ stopping, and giving me a blank graph. I ran a few tests (w/ kernel restarts; batch size = 32):
- NB §V. & §Va. I ran SGugger’s notebook implementation and the ‘stock’ fastai version without any non-default transforms to make sure what should work, does, successfully.
- I then went code-digging into
fasta/transforms.pyto confirm nothing fishy was happening when I initialized the ModelData object – and everything seemed in order. -
NB §Vb.
I then compared 3 ways of initializing the Data Loader:tfms_from_stats(imagenet_stats, sz),tfms_from_model(darknet53, sz), andtfms_from_model(resnet50, sz).
This was to confirm that tfms_from_model worked the same as tfms_from_stats if the model was a non-Inception arch. (sanity-checking against the fastai transforms.py code). I used resnet50 because SGugger used it in his notebook and I wanted a further sanity-check that passing in this new arch. (darknet53) wouldn’t change anything.
I got some strange behavior running .lr_find():
-
tfms_from_statsandtfms_from_model(darknet53, sz)both ‘failed’ (blank plot) about twice each (around iteration 12 ~ 15) with a negative loss, before successfully showing a lr-vs-loss plot that looked similar to SGugger’s. -
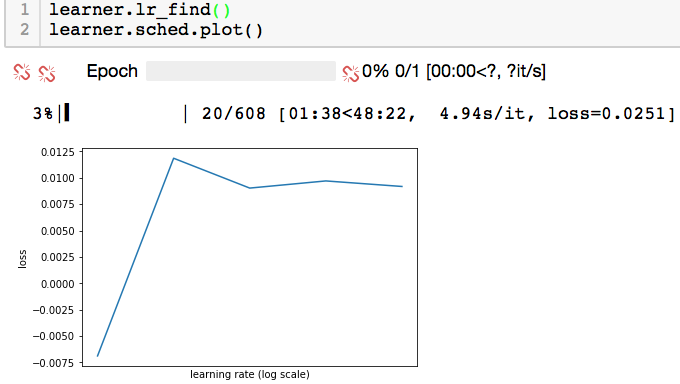
tfms_from_model(resnet50, sz)‘failed’ 4 times before successfully displaying a lr-loss plot, but the plot looked very ‘low-res’ with only 4 line-segments. A subsequent run produced a similar plot, and a third run finally produced a plot just like the other ‘successful’ ones.
Couple notes: The plots that ‘look right’ generally make it past 50 or 100 iterations. The ‘low-res’ plots don’t make it to 50. The ‘failed’ runs usually stop at a dozen-or-so iterations. They seem to stop after spending too many iterations with a negative loss value (usually something like -0.0003… or thereabouts).
A ‘good looking’ plot:
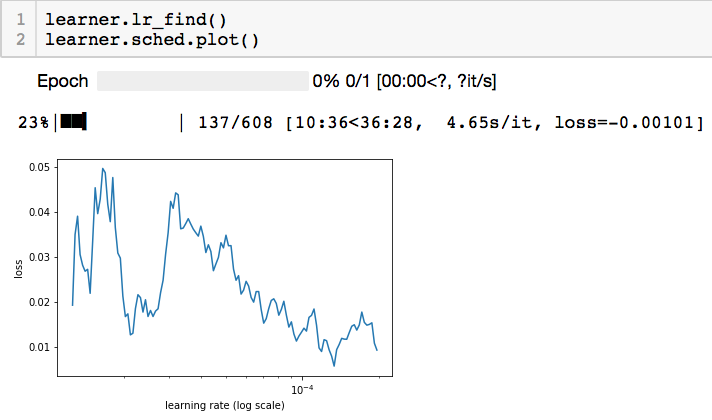
A ‘low-res’ plot (exact same setup as above):
Just wanted to make sure I’m not doing anything obviously wrong; and share what I’m up to. I figure I’ll just find out what the right training regimen for a giant dataset like ImageNet is – if anyone knows: I’m all ears.
Hi Borz,
You shouldn’t use the nll_loss since there’s no softmax at the end of the darknet, you should use the CrossEntropyLoss (which combines the softmax and the nll_loss). That’s why you get a negative loss that makes the lr_finder do weird things.
It’s more efficient to do it this way than put the log_softmax at the end of the model and then use the nll_loss I think.
4 Likes
I made this same mistake yesterday…
Interesting. I did some digging to find out why fastai was setting .crit to nll_loss by default \longrightarrow turns out if the ModelData object’s .is_multi attribute is False (and .is_reg too) then this is the default.
Maybe that makes sense because the model’s ultimately choosing a single class foreach anchor box? – not sure if that’s by design or WIP.
Anyway, I made sure to set crit=F.cross_entropy, and here’s what I got:
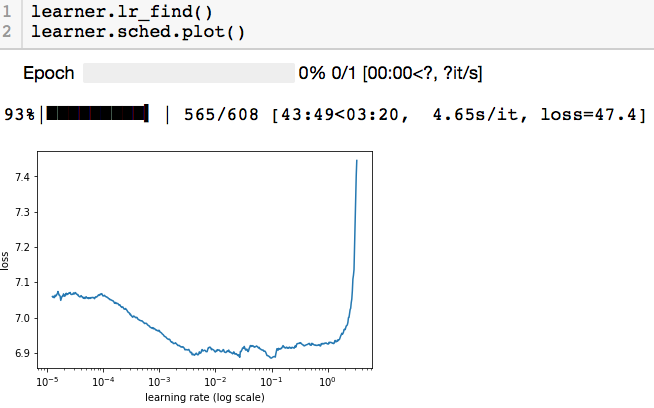
The shape looks like what you’d expect, and so does the loss for a blank-slate model.
I’m going to take a look at using Cyclic Learning Rates for training this on ImageNet. I’m not sure if it’s worth it to train a new model from scratch on ImageNet – but I figure if I want a ‘new’ pretrained model: that’s the way to go; and I guess it should only really take a day or two.
Thanks for the pointer, btw!
Where are you seeing that? I suspect it may be a mistake…
The _get_crit(.) method in Learner is redefined in ConvLearner. There:
if not hasattr(data, 'is_multi'_: return super()._get_crit(data)
is not run, instead:
return F.l1_loss if data.is_reg else F.binary_cross_entropy if data.is_multi else F.nll_loss
runs, and F.nll_loss is returned.
I did a bunch of pdb.set_trace()'s and print outs in the learner.py and conv_learner.py code in testing this.
The setup I used:
sz = 256
bs = 32
darknet53 = darknet.darknet_53()
tfms = tfms_from_model(darknet53, sz)
model_data = ImageClassifierData.from_paths(PATH, bs=bs, tfms=tfms, val_name='train')
learner = ConvLearner.from_model_data(darknet53, model_data)
NOTE: In darknet.py I changed the import line from .layers import * to from fastai.layers import * \rightarrow that’s how I imported the fastai darknet model.
Thanks! That was a recent PR from someone that I didn’t study closely - what would you suggest instead?
I’m not sure. We want cross entropy in this case, but I guess there are cases were nll loss is desired? is_multi looks like it’s for multiple label – not more-than-two classes. But the loss-fn logic has been ‘working right’ in the past…
I’m taking a look now at what happens under the hood with CIFAR-10 & resnet18 to get a better idea. I’ll ping you when I find something.
@jeremy alright so… what I found is interesting and confusing. The pretrained resnet18 model uses nll_loss. I went to the pytorch definition and didn’t see a softmax defined in any forward fn. I took a look at conv_learner.py’s commit history… and looks like we’ve always been using nll_loss. At least since 18 November 2017.
This contradicts @sgugger’s condition that NLL should be used with Softmax, otherwise Cross Entropy should be used – since it combines the two.
But… Sylvain’s advice does work… but we’ve also been able to train image classifiers this whole time…
There’s another issue with the learner failing to initalize with ConvLearner.from_model_data(resnet18, md), though I’m not sure if that problem’s related.
Here’s the notebook I’m testing in. I don’t have a recommendation yet – I have to resolve these apparent contradictions first.
Oh! okay, wow. Fastai’s working normally: it’s because the model isn’t pretrained. I’ll submit a PR adding an nn.LogSoftmax layer at the end.
Fastai’s ConvnetBuilder run by ConvLearner.pretrained places a Log Softmax output layer when it builds the classifier head atop the pretrained model… Our new Darknet is being called .from_model_data and so ConvnetBuilder is never called \Longrightarrow the linear/classifier head is never installed: No Log Softmax output layer.
So… when the self.crit = ... else self._get_crit(data) is called during learner initialization:
It’s not multi-label clsfn, it’s not regression, it’s standard classification: so the criterion is set to F.nll_loss. For a pretrained model constructed via ConvnetBuilder this is perfect: cross entropy loss is a log softmax wrapped inside negative-log-likelihood loss.
This also sheds light on why ResNet18 was failing to initialize when called .from_model_data: the setup steps fastai was expecting weren’t done since ConvnetBuilder never ran.
I’m running some tests now, when they’re done I’ll put them in a gist and link it in the PR.
I wanted to see when darknet as a function and as a model – vs resnet18 for comparison – worked with Convlearner. Here’s a table of what works/doesn’t:
| ConvLearner | resnet18 |
resnet18() |
darknet_53 |
darknet_53() |
|---|---|---|---|---|
.pretrained |
√ | X | X | X |
.from_model_data |
X | √ | X | √ |
As far as I can tell, importing and building a pytorch model via resnet18(), or as a learner object in fastai with .pretrained doesn’t create any output activation layer – fastai’s ConvLearner logic assigns a nn.nll_loss criterion, and that’s it. The pytorch definition doesn’t do it for you either. So, since we don’t have pretrained weights yet, I’ll just add a Log Softmax layer to the end of darknet – that way .from_model_data will work fine, and the nll_loss will work as Cross Entropy. I don’t know how adding a new set of pretrained weights to fastai works, but I’ll leave that for later.
And test result: works exactly as you’d expect when that Log Softmax layer is in:

learner summary:

2 Likes
Hello All, Is there any plans to create a full fast ai yolov3 like the ssd in lesson 9?
Hi Borz
I got confused about these questions for a long time.
If you figured out how to use the other pretrained models in fastai, please let me know.
thanks for you sharing.
If I have it right: building Learners from pretrained models requires you to put in the model without initializing it.
I think that’s because conv_learner.ConvnetBuilder is used under the hood to construct the network. And they also need somewhere to get their pretrained weights from – I mostly forgot how that works sorry, but there is a process to add them to fastai, so you could look around.
If you’re not using .pretrained, you have to pass in an initialized network to the Learner (or ConvLearner or etc). You’re also fully responsible for making sure your architecture is what you want it to be (ie: if your last layer doesn’t have an activation but you want cross entropy loss you have to set the learner’s .crit accordingly).
Nutshell:
if your model is network
- want
learner.pretrained: usenetwork(and be sure fastai knows how to get the pretrained weights) - want
learner–.from_model_dataor custom: usenetwork()
Also check out ConvnetBuilder in fastai/conv_learner.py – it’s how fastai automatically builds good classifier heads, and we use it in one of the later lessons (Lesson 8/9 pascal after defining the regression head).
2 Likes