I was thinking of this one, since it just reads in the config file:
2 Likes
@sgugger @emilmelnikov I’ve reformatted the yolo v3 config file (without the localization bit) to make it more easy to read and see what’s going on. Hopefully this helps you check your implementation against the original:
Thanks Jeremy, this is very helpful.
I changed the notebook accordingly and I think it’s the real darknet-53 now. Trained it for a few epochs and it seemed to work.
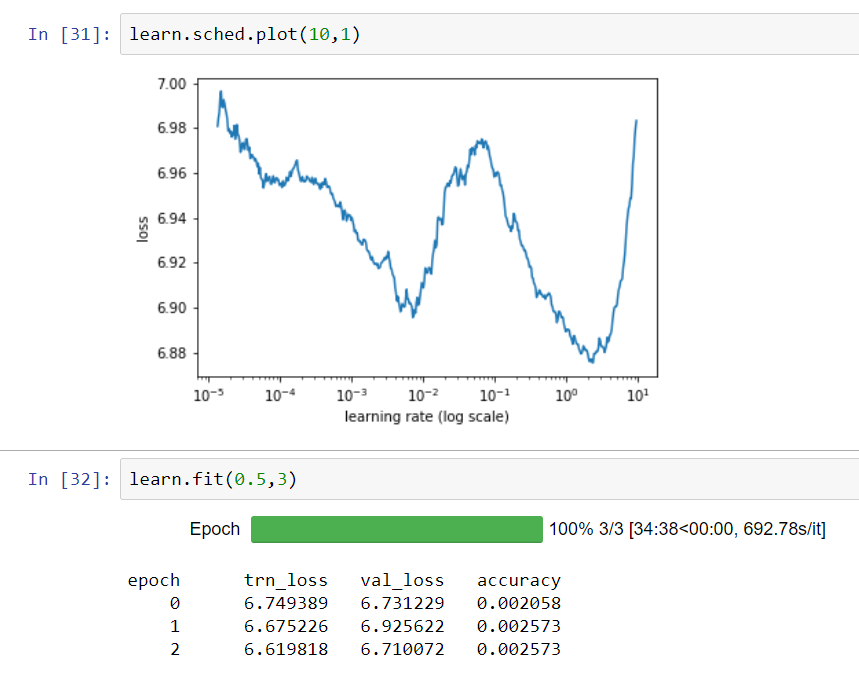
2 Likes
OK that’s great @sgugger I’ll try it out on full imagenet tomorrow - please pop it in the models/ dir and submit a PR.
@emilmelnikov if you have a moment maybe you can compare it to your implementation (speed and accuracy and code)? Let us know if you think there’s room to improve! 
Well after studying our existing resnet code it appears the stride-2 conv has already been moved to the spot they suggest…
Hi!
I’ve checked out your implementation. Looks very cool.
One thing though, In your ConvBN you have padding as parameter but when creating convolutional layer you always set padding to 1(which seems like a correct behavior, because yolo3 config also always use pad=1).
And in DarknetBlock you have:
+ self.conv1 = ConvBN(ch_in, ch_hid, kernel_size=1, stride=1, padding=0)
+ self.conv2 = ConvBN(ch_hid, ch_in, kernel_size=3, stride=1, padding=1)
so you’re trying to set padding to zero in first conv layer but the parameter later gets ignored. (Which again, I think it should be, as this config from yolo3 suggest).
2 Likes
You’re absolutely right. I forgot to remove all those paddings after setting to one every time. It doesn’t change anything after but it’s way cleaner this way!
Thanks for catching this, I’ve updated the notebook with the correction.
1 Like
Hi, again! Ifter looking at darknet source code I’ve realized that ‘pad’ and ‘padding’ aren’t the same thing.
As you can see from here, when pad is equal to 1, then padding is set to (filter_size / 2). So padding=0 whould be the correct way for convolutional layers with kernel_size=1. Which makes much more sense, since why whould we need a padding for convolution which only sees one cell at a time and hence doen’t change shape of the actications from previous layer.
2 Likes
You’re right again, I went to fast while putting that padding to 1 for every layer (which only worked because of another bug anyway: I always forced the kernel_size to 3 in BNConv…)
I’ve updated again the notebook and my PR, thanks a lot for catching all of this!
Sorry, was a bit busy, and now I’m having strange problems with CUDA OOM errors. This is the model itself: https://github.com/emilmelnikov/darknet53-pytorch
I’ve also tried to write training code using approximately the same settings as in the yolov3.cfg: SGD with learning rate 1e-3, momentum 0.9, weight decay 5e-4. Apparently, there are also some settings for data augmentation (angle, saturation, exposure, hue), but I didn’t succeed to find out exactly how DarkNet framework does it.
A couple of interesting notes:
- Leaky ReLU uses 0.1 negative factor instead of 0.01 in PyTorch
- BatchNorm uses 0.01 momentum for running mean and variance instead of 0.1 in PyTorch
- BatchNorm is applied after convolution and before activations
Of course, feel free to steal anything you find useful from the code.
1 Like
Oh, I hadn’t noticed this one.
Thanks for sharing your code, will compare our approaches!
Edit: If I’m not mistaken, there is a bug in your shortcuts: the leaky_relu is applied after summing the input and the output of the second conv.
In the original ResNet it is true, but in darknet it seems to be different.
The shortcut layer is defined as follows:
[shortcut]
from=-3
activation=linear
It looks like shortcut_cpu is a linear combination of it’s inputs.
The linear activation is just an identity function.
Yeah but in the implementation in pytorch they write after:
elif block['type'] == 'shortcut':
from_layer = int(block['from'])
activation = block['activation']
from_layer = from_layer if from_layer > 0 else from_layer + ind
x1 = outputs[from_layer]
x2 = outputs[ind-1]
x = x1 + x2
if activation == 'leaky':
x = F.leaky_relu(x, 0.1, inplace=True)
elif activation == 'relu':
x = F.relu(x, inplace=True)
outputs[ind] = x
Edit: which means you’re right since with shortcut, we’ve got activation=linear, which isn’t leaky or relu.
Sorry!
2 Likes
Just FYI the implementation in pytorch isn’t from the original authors, and in my experience about 98% of attempts to replicate papers in DL are wrong. So take them with a grain of salt, unless they show that they’ve replicated the results from the paper!
1 Like
Just read through the PR and the implementation is very nice and clean - thanks! Will try it out now.
Like my four or five first attempts to replicate this darknet ![]()
I think I got it right now, all thanks to emilmelnikov. The last version in the PR seemd to be training properly:
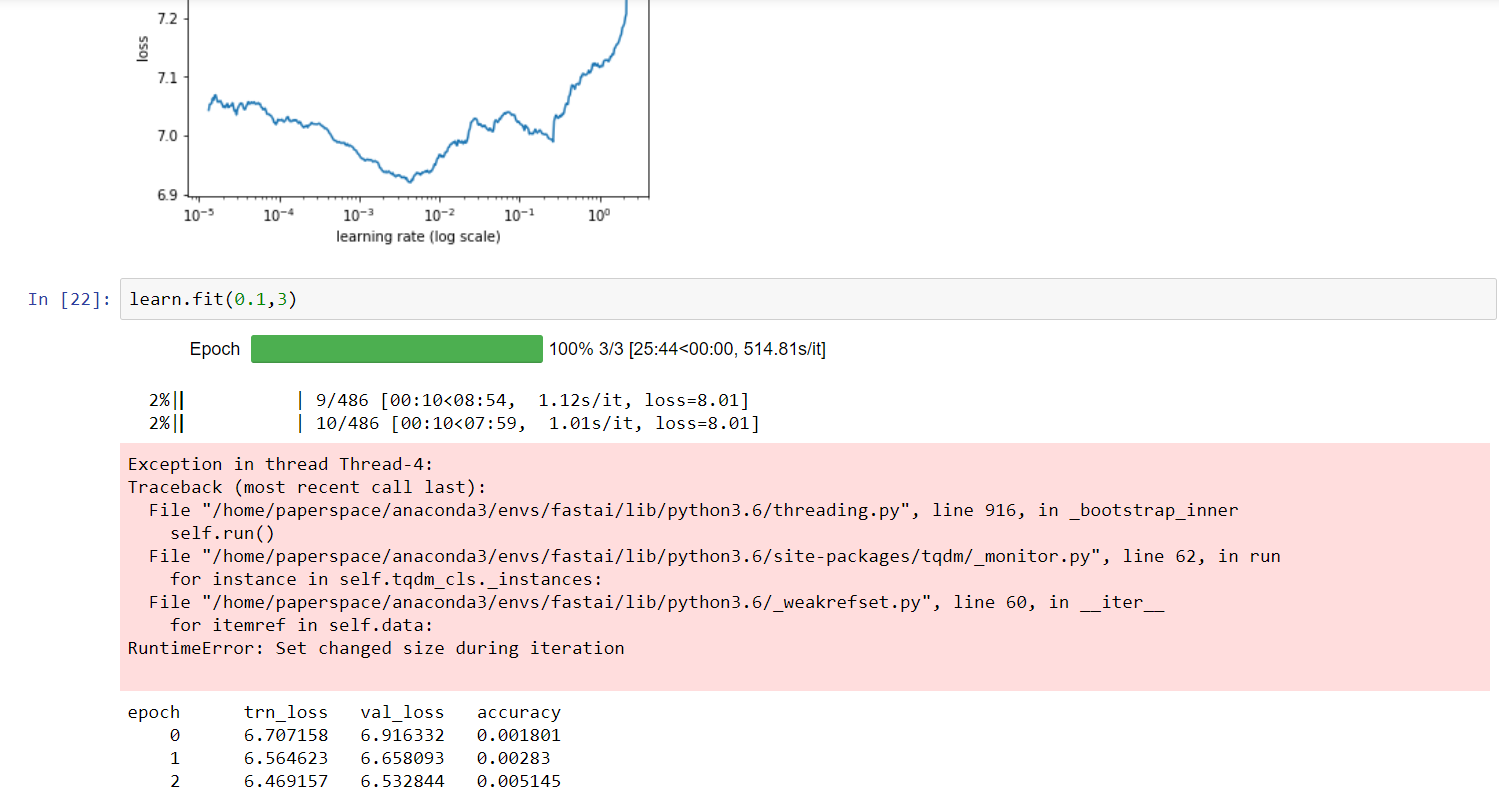
1 Like
FYI I just pushed a minor fix, which is to remove the log_softmax. In pytorch models generally don’t include that, since it’s built in to the cross_entropy loss function.
I also added a couple of smaller versions of the model for us to try out.
Bad news: I can’t fit batch size 128 on a 16GB GPU. Any thoughts on how to decrease memory needs?
I’ve created a copy of smaller versions of the model to try. But the RAM use seems very high. Have you guys tried counting the number of parameters and comparing that with the reference implementation to ensure it’s the same?
OK I’ve just pushed a version of darknet.py that allows different numbers of groups, and has a variety of ‘mini’ versions that all fit in 16GB when using half precision and batch size of 128. They should also fit in 8GB with single precision with batch size 32.
A brief sum on my implementation gives 41,609,928 parameters. Not sure how many there are in the original implementation.