I am starting out experimenting with structured data. This is post Lesson 4 and trying to run the proc_df function on my data-frame.
It gives me the following error:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-52-b85f40a645ed> in <module>()
----> 1 df, y, nas, mapper = proc_df(train, 'is_attributed', do_scale=True)
~/projects/fastai/fastai/structured.py in proc_df(df, y_fld, skip_flds, do_scale, na_dict, preproc_fn, max_n_cat, subset, mapper)
425 if na_dict is None: na_dict = {}
426 for n,c in df.items(): na_dict = fix_missing(df, c, n, na_dict)
--> 427 if do_scale: mapper = scale_vars(df, mapper)
428 for n,c in df.items(): numericalize(df, c, n, max_n_cat)
429 res = [pd.get_dummies(df, dummy_na=True), y, na_dict]
~/projects/fastai/fastai/structured.py in scale_vars(df, mapper)
322 map_f = [([n],StandardScaler()) for n in df.columns if is_numeric_dtype(df[n])]
323 mapper = DataFrameMapper(map_f).fit(df)
--> 324 df[mapper.transformed_names_] = mapper.transform(df)
325 return mapper
326
~/anaconda2/envs/fastai/lib/python3.6/site-packages/sklearn_pandas/dataframe_mapper.py in transform(self, X)
313 stacked = stacked.toarray()
314 else:
--> 315 stacked = np.hstack(extracted)
316
317 if self.df_out:
~/anaconda2/envs/fastai/lib/python3.6/site-packages/numpy/core/shape_base.py in hstack(tup)
286 return _nx.concatenate(arrs, 0)
287 else:
--> 288 return _nx.concatenate(arrs, 1)
289
290
ValueError: need at least one array to concatenate
I dont really understand what is going on here.
This is while trying to do the Talking Data Kaggle competition which is on right now.
This is how I call it:
df, y, nas, mapper = proc_df(train, 'is_attributed', do_scale=True)
And this is how train looks:
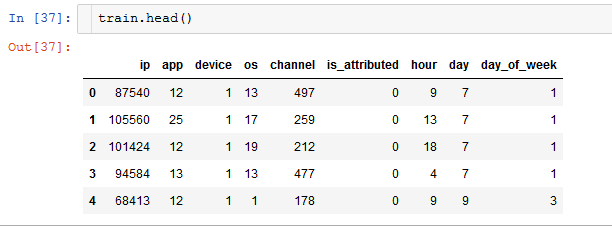
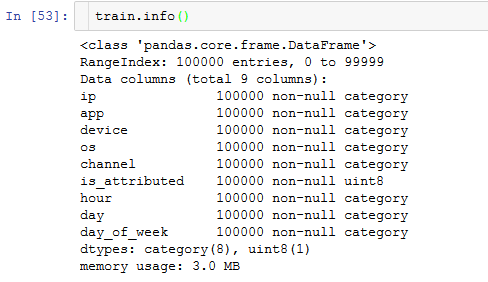
Anyone here that can help me understand what is going wrong?
It seems to have to do with the scaling, and I am thinking it could be because there is not enough variance possibly for some of the columns?