Hello!
I have encountered some issues with fastai v2 (I am using the 2.3 version), that might be related to the code itself or they might be just caused by Google Colab. I thought that it would be a good idea to share these issues at this forum. To give a bit of context, I am facing a problem that should be really simple: To train a CNN that classifies images into 5 categories, and there are about 9000 images in total. The problems that I have found are the following:
-
It is impossible to train a neural network using the cnn_learner setting freeze_epochs = 0. I get the following error:
[Errno 2] No such file or directory: ‘models/model.pth’- Here is my code for that bit (for some directory ‘dir’):
path = Path(dir)
pcas = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
get_y=parent_label,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
item_tfms=Resize(224)
,batch_tfms=aug_transforms(mult=0.2,do_flip=False)
)dls = pcas.dataloaders(path,bs=50)
learn = cnn_learner(dls, resnet34, metrics=accuracy)
learn.fine_tune(epochs = 20,freeze_epochs=0, base_lr= 0.007, cbs=[ShowGraphCallback(), SaveModelCallback(monitor=‘accuracy’)] )
- I tried to unfreeze the model, using learn.unfreeze(), but it does no change anything.
- Now, if I set freeze_epochs = 1, it works as it is supposed to. However, I believe that pre-training the last layer in this situation might not be the best option, as the more freeze epochs I use, the worse accuracy I get. In fact, I consistently get about 80% accuracy and once (I can’t remember how did I do it) i think I was able to set freeze_epochs = 0 on the first training, and I got up to 98% accuracy. I had not been able to replicate this result, but I managed to save the model.
- One solution I thought of was defining a learner, training it for one freeze epoch (it usually takes about 20 minutes the first time I do it, I don’t know if it should take so much time) and then deleting it. If I define now a new learner and I set freeze_epochs = 0, it works without showing any error. The problem with this method is that there will always be some residual memory about the previous learner that will affect the training. In order to delete completely the previous learner I do the following:
learn = None
del(learn)
import gc
gc.collect()
torch.cuda.empty_cache()What happens is that, if the first learner had been trained up to an accuracy of 70%, and if I define a new learner after deleting the first one and I start training it, it will start with an accuracy of about 70%. If the first one ended up with an accuracy of 40%, the new one will start its training with an accuracy of about 40% too. I got these results several times so it does not look like it happens by chance. There must be some kind of residual memory of the previous learner that influences the new one. The only way to delete completely all the information about the previous learner that I have found is to Factory Reset the Runtime. If I do that, then I have to wait again for about 20 minutes and I am forced to train with at least one freeze epoch.
- Another option that I have tried is to define a learner with a different resnet, as the missing file appears to be created after defining the first learner. If I try now to fine tune the new learner with freeze_epochs = 0, I get a different, really long error message:
RuntimeError Traceback (most recent call last)
<ipython-input-23-faa4d85e2a4e> in <module>()
----> 1 learn.fine_tune(epochs = 2,freeze_epochs=0, base_lr= 0.007, cbs=[ShowGraphCallback(), SaveModelCallback(monitor=‘accuracy’)] )
13 frames
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
1050 if len(error_msgs) > 0:
1051 raise RuntimeError(‘Error(s) in loading state_dict for {}:\n\t{}’.format(
→ 1052 self.class.name, “\n\t”.join(error_msgs)))
1053 return _IncompatibleKeys(missing_keys, unexpected_keys)
1054
RuntimeError: Error(s) in loading state_dict for Sequential:
Missing key(s) in state_dict: “0.4.0.conv3.weight”, “0.4.0.bn3.weight”, “0.4.0.bn3.bias”, “0.4.0.bn3.running_mean”, “0.4.0.bn3.running_var”, “0.4.0.downsample.0.weight”, “0.4.0.downsample.1.weight”, “0.4.0.downsample.1.bias”, “0.4.0.downsample.1.running_mean”, “0.4.0.downsample.1.running_var”, “0.4.1.conv3.weight”, “0.4.1.bn3.weight”, “0.4.1.bn3.bias”, “0.4.1.bn3.running_mean”, “0.4.1.bn3.running_var”, “0.4.2.conv3.weight”, “0.4.2.bn3.weight”, “0.4.2.bn3.bias”, “0.4.2.bn3.running_mean”, “0.4.2.bn3.running_var”, “0.5.0.conv3.weight”, “0.5.0.bn3.weight”, “0.5.0.bn3.bias”, “0.5.0.bn3.running_mean”, “0.5.0.bn3.running_var”, “0.5.1.conv3.weight”, “0.5.1.bn3.weight”, “0.5.1.bn3.bias”, “0.5.1.bn3.running_mean”, “0.5.1.bn3.running_var”, “0.5.2.conv3.weight”, “0.5.2.bn3.weight”, “0.5.2.bn3.bias”, “0.5.2.bn3.running_mean”, “0.5.2.bn3.running_var”, “0.5.3.conv3.weight”, “0.5.3.bn3.weight”, “0.5.3.bn3.bias”, “0.5.3.bn3.running_mean”, “0.5.3.bn3.running_var”, “0.6.0.conv3.weight”, “0.6.0.bn3.weight”, “0.6.0.bn3.bias”, “0.6.0.bn3.running_mean”, “0.6.0.bn3.running_var”, “0.6.1.conv3.weight”, “0.6.1.bn3.weight”, “0.6.1.bn3.bias”, “0.6.1.bn3.running_mean”, “0.6.1.bn3.running_var”, “0.6.2.conv3.weight”, “0.6.2.bn3.weight”, “0.6.2.bn3.bias”, “0.6.2.bn3.running_mean”, “0.6.2.bn3.running_var”, “0.6.3.conv3.weight”, “0.6.3.bn3.weight”, “0.6.3.bn3.bias”, “0.6.3.bn3.running_mean”, “0.6.3.bn3.running_var”, “0.6.4.conv3.weight”, “0.6.4.bn3.weight”, “0.6.4.bn3.bias”, “0.6.4.bn3.running_mean”, "0.6…
Clearly, something is not working the way it should. However, if I set again freeze_epochs = 1, it works like the first time.
- My question is: Is there any way to train a CNN using transfer learning in fastai without freeze espochs? What are those errors that appear when I try to do it?
- When I load a saved model, it classifies all images into the same category or something along those lines. This becomes clear if I plot its confusion matrix and if I validate the model and get accuracy (about 20%, as there are 5 categories).
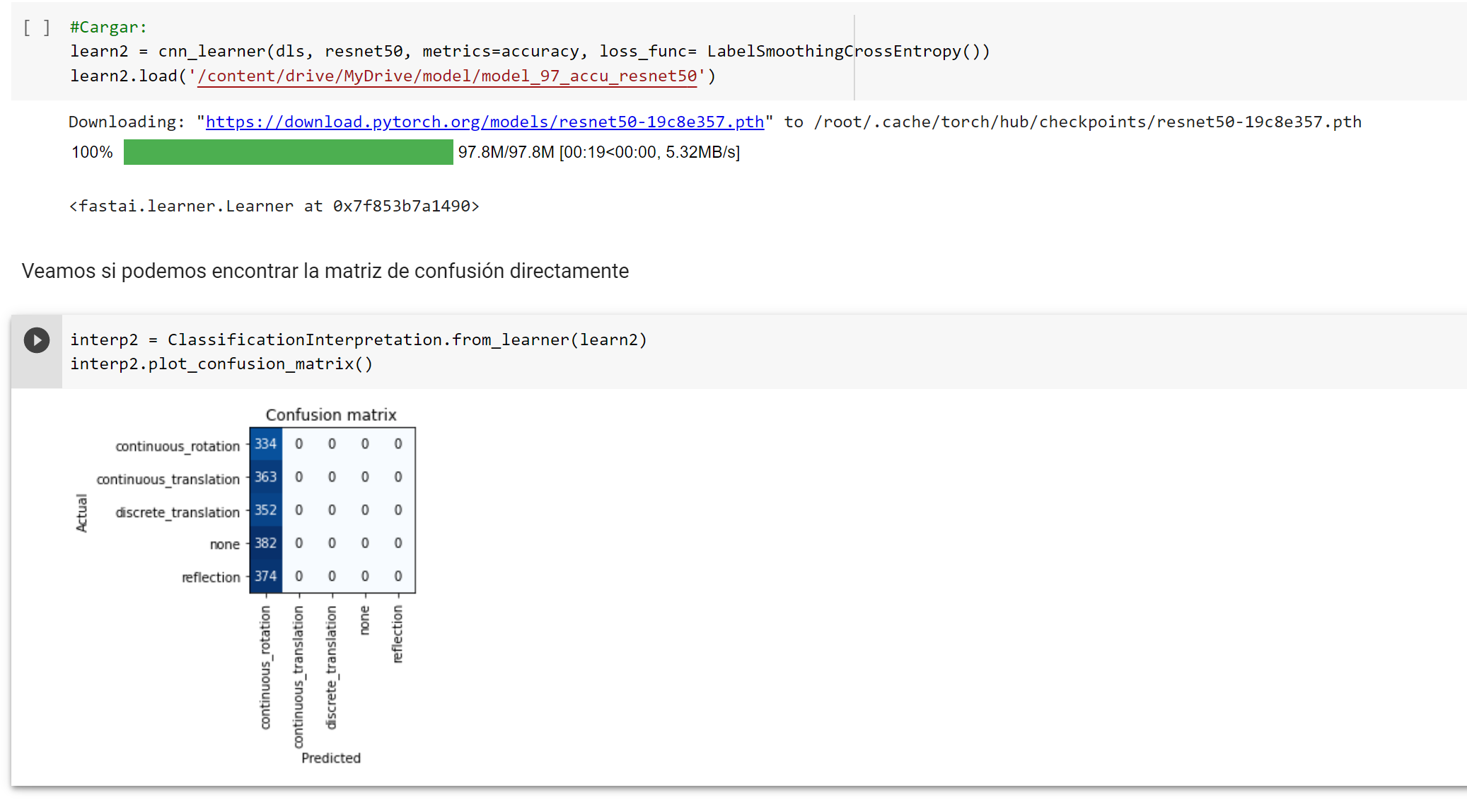
Now, if I train the imported model for 1 epoch, it goes back to almost the same accuracy it had before saving (slightly below the original one, about 2-5% less accuracy).
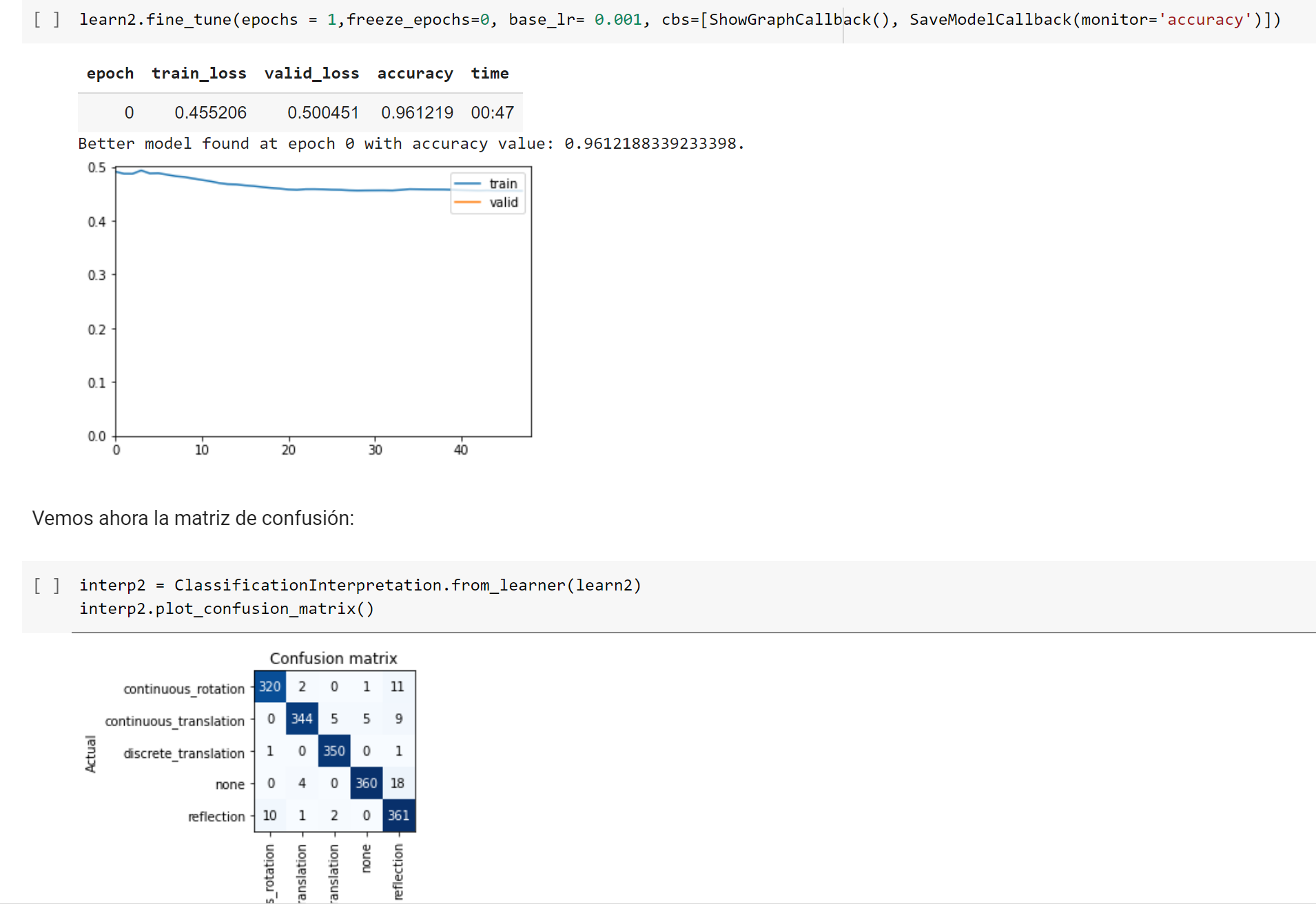
My questions: Why isn’t it possible to import a model and use it directly? Why do I have to train it again for one epoch or more in order for it to work? Why can’t the model arrive to the same accuracy as the original one?
- This one is not a big deal, but I believe it is worth noting that the way you have to import an image in order to make a prediction using a CNN, learn.predict(img), is a bit unclear. It should be a PIL image, but using “pil.Image.open()” won’t work. Using the tools integrated in fastai, one could think that “fastai.vision.all import Image im = Image.open(im_dir)” should work, but it doesn’t, as it has to be of the type “fastai.vision.core.PILImage”. If I cast the image to this type (“im_t = cast(im, fastai.vision.core.PILImage”)), I am still unable to do it, as I get an error stating that im_t doesn’t have an attribute called “crop” or something similar. I think that in fastai v1 you could use the function load_image() which doesn’t exist in fastai v2. The only way that I have been able to achieve this is by using “im = PILImage.create(test_im_dir)”. That is why I think it is a bit unclear.