Hi @jeremy, and any others who can assist!
I am trying to see if I can get the Windows version of Pytorch running, so far yes I can - but I have encountered a strange behaviour when running texts_from_folders in the fast.ai library.
Even though my default python encoding (using sys.getdefaultencoding() and sys.getfilesystemencoding()) is utf-8, for some reason (I believe its because I am in the Windows environment), when the call to texts.append(open(fpath).read()) in that function runs I get an encoding error.
Since the function doesn’t specify encoding, the system goes to fetch its default encoding - which is at this point uses the standard Windows unicode encoding of cp1252 instead of the required utf-8.
So I get this error:
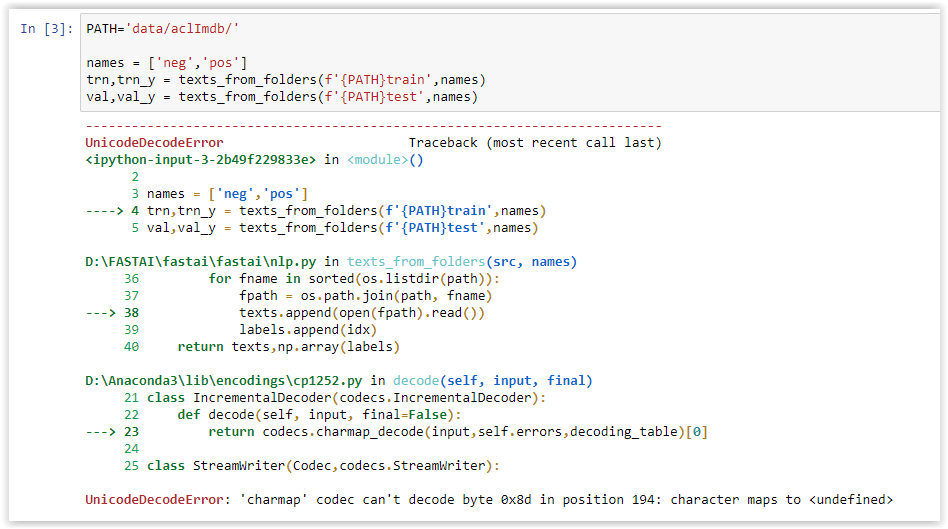
To test this I made a local version of texts_from_folders and specified the encoding as utf-8 (see below), and now it correctly loads. Short of getting another parameter for the fast.ai function so we can pass in encoding (which BTW I think would be a good idea), is there any way I can force the open() function to use utf-8 by some sort of system setting?
I have read many blogs about this but nobody seems to have quite nailed it - there are conversations about re-instating a missing sys.setdefaultencoding() but even if I was to do this I’m not sure it would be helpful - as my default is utf-8, it just misbehaves at the point of using the open() function…
def my_texts_from_folders(src, names):
texts,labels = [],[]
for idx,name in enumerate(names):
path = os.path.join(src, name)
for fname in sorted(os.listdir(path)):
fpath = os.path.join(path, fname)
texts.append(open(fpath, encoding="utf8").read())
labels.append(idx)
return texts,np.array(labels)