I recently wrote an article to show how to incorporate pre-trained Pytorch-transformers models into fastai framework. The main issue needed to be addressed is that the Pytorch-transformer models would yield a tuple containing not only the forward output we are familiar with, but also other states such as attention weights. This issue is more detailed at here.
In my article, in the beginning, I used a “dumb” way by changing the fundamental training loop in the loss_batch function in fastai.basic_train module. This solution works great with no problems. However, it is not the best way when we have a flexible fastai callback system!
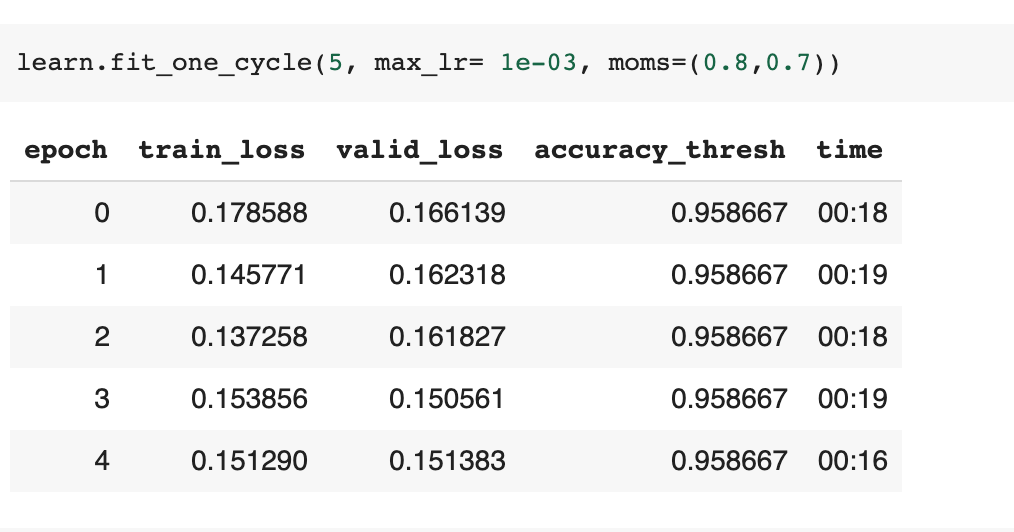
With the reminder from Jeremy, and help from @waydegilliam, I managed to write a callback that would do the work but with a small issue that I have no idea: the metric, accuracy_thresh, is not changing across epochs. The training and validation losses are changing but the metric stays the same.
I have put my results in this Google colab for your convenience. I would appreciate if anyone could shed some light on the problem of this issue and how to solve them if possible.
Thanks for your reply @sgugger I really appreciate your help.
That is what I thought and I spent a whole afternoon trying to diagnose why the metric is not changing.
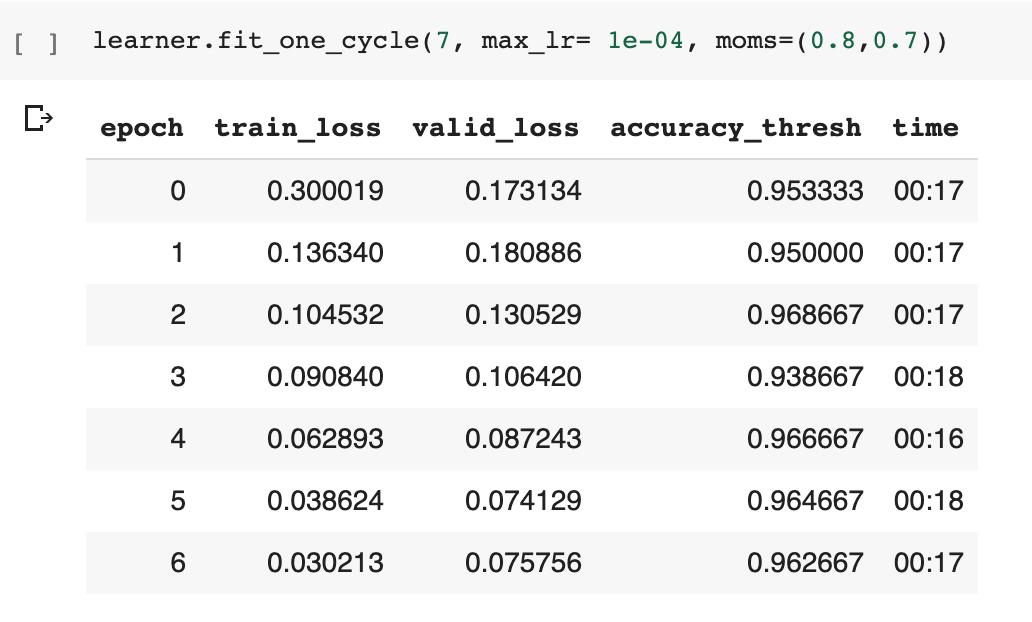
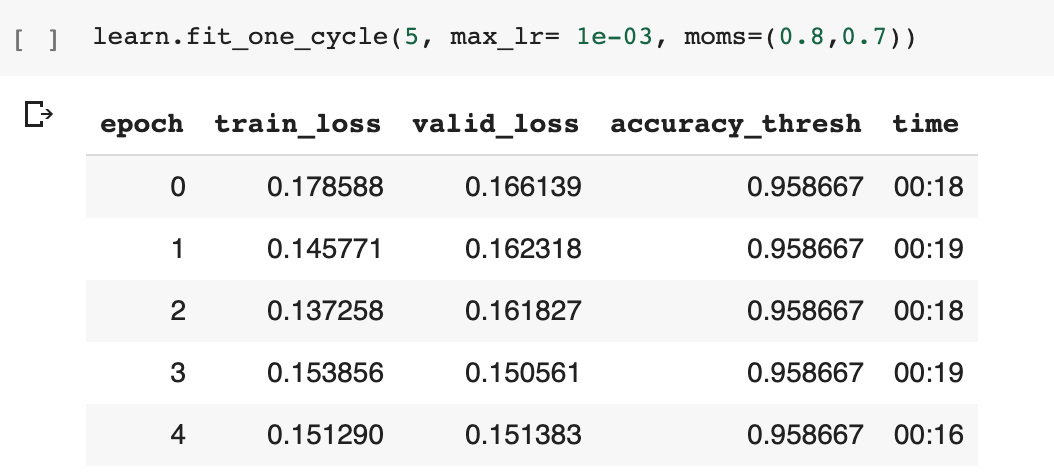
However, when I tried my “dumb” way which is to change toe basic training loop in loss_batch function:
def loss_batch_bert(model:nn.Module, xb:Tensor, yb:Tensor, loss_func:OptLossFunc=None, opt:OptOptimizer=None,
cb_handler:Optional[CallbackHandler]=None)->Tuple[Union[Tensor,int,float,str]]:
"Calculate loss and metrics for a batch, call out to callbacks as necessary."
cb_handler = ifnone(cb_handler, CallbackHandler())
if not is_listy(xb): xb = [xb]
if not is_listy(yb): yb = [yb]
out = model(*xb)
#pdb.set_trace()
out = out[0] ######### change the training loop at here
out = cb_handler.on_loss_begin(out)
if not loss_func: return to_detach(out), yb[0].detach()
loss = loss_func(out, *yb)
if opt is not None:
loss,skip_bwd = cb_handler.on_backward_begin(loss)
if not skip_bwd: loss.backward()
if not cb_handler.on_backward_end(): opt.step()
if not cb_handler.on_step_end(): opt.zero_grad()
return loss.detach().cpu()
The metric is moving and the training loss decreases steadily: