=== 2020.05.21 ===
-
Load cache with different args
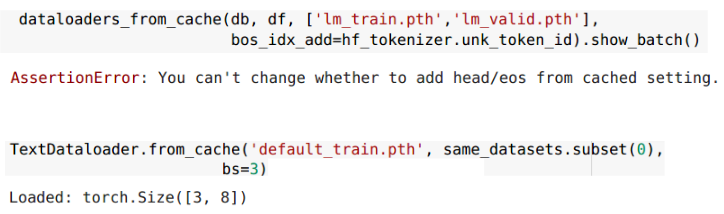
When loading cachedTextDataloader, you can change setting forTfmDL, such asbs,before_batch…, and also some ofTextDataloader(sort_by_len,…). Also it will tell you when you try to change invalidly.
-
Loading bar
Now you won’t be worried about if there is bug but know that it was just need more time.