Sorry if this is an inappropriate or obvious question, but I’m new. I searched google and the forums but couldn’t find what may be a simple answer to those more knowledgeable (I am not a coder).
I’ve managed to cobble together code that reads a 3 minute video, then using a resnet cnn trained on labeled “interesting” frames it predicts “interesting” segments of the video, then I use MoviePy to stitch together those clips into a 30 second highlight. Everything works great, it’s just really slow (on my laptop GTX-960m and Google Colab K80s).
My question: Is there a way to avoid writing video frames to disk (as .jpg files) before reading them with learn.predict(open_image(file))? I do not know how to troubleshoot what is taking so long, but I suspect an unnecessary i/o to disk isn’t helping.
Relevant code:
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
...
vid = cv2.VideoCapture(str(testvid))
while ret:
ret, frame = vid.read()
cv2.imwrite(file, frame)
p = learn.predict(open_image(file))
I’ve tried different combinations of cv2.imencode and decode as well as trying open_image(frame) but they all throw errors inside the fast.ai library as open_image is looking for an image “file”.
I’ve looked at others attempts to write custom video dataloaders but that is way above my paygrade. Am I missing something simple?
What you need to do is convert the opencv frame to a pytorch tensor. You can do it as follows: t = 1 - torch.tensor(np.ascontiguousarray(np.flip(im, 2)).transpose(2,0,1))
In OpenCV images are stored like (height, width, channels) whereas in pytorch you expect (channels, height, width) (thats the transpose part). Further OpenCV stores as BGR instead of RGB (therefore the flip). Making the array contiguous is necessary because the flip actually does not change the underlying data at all and only modifies the iterator (which seems to not work when further transposing). Also in the small test that I did OpenCV loaded a uint8 image for me which is also reversed (0 black vs. 0 white), therefore the 1 - torch.tensor(...)
Edit: Oh yeah, if you want a fastai image, you will then also need to do Image(t)
Thanks. I think I understand the tensor manipulation part but I’m still having trouble with the learn.predict part. Again, sorry since I’m not a coder, but learn.predict works with open_image output (there is some magic with applying transforms in there I don’t fully understand). Where in my code would I put ‘t’?
trying: img=Image(t) and img=PIL.Image(t) error says: ‘module’ object is not callable
trying: open_image(t) error says: ‘Tensor’ object has no attribute ‘seek’ / ‘read’
trying: learn.predict(t) error says: ‘Tensor’ object has no attribute ‘apply_tfms’
Seems to me like fastai\vision\image.py is trying to open a file…
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
~\Anaconda3\envs\fai\lib\site-packages\PIL\Image.py in open(fp, mode)
2637 try:
-> 2638 fp.seek(0)
2639 except (AttributeError, io.UnsupportedOperation):
AttributeError: 'Tensor' object has no attribute 'seek'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
<ipython-input-73-288824100e37> in <module>
14 t = 1 - torch.tensor(np.ascontiguousarray(np.flip(frame, 2)).transpose(2,0,1))
15 # img = Image(t)
---> 16 img = open_image(t)
17 p = learn.predict(img)
18 pred = p[1].item()
~\Anaconda3\envs\fai\lib\site-packages\fastai\vision\image.py in open_image(fn, div, convert_mode, cls, after_open)
391 with warnings.catch_warnings():
392 warnings.simplefilter("ignore", UserWarning) # EXIF warning from TiffPlugin
--> 393 x = PIL.Image.open(fn).convert(convert_mode)
394 if after_open: x = after_open(x)
395 x = pil2tensor(x,np.float32)
~\Anaconda3\envs\fai\lib\site-packages\PIL\Image.py in open(fp, mode)
2638 fp.seek(0)
2639 except (AttributeError, io.UnsupportedOperation):
-> 2640 fp = io.BytesIO(fp.read())
2641 exclusive_fp = True
2642
AttributeError: 'Tensor' object has no attribute 'read'
You are mixing PIL Image with fastai Image there.
so PIL is your basic python image library that is used for example in open_image to read images from disk (given a file name). This open_image function further converts the PIL Image to a PyTorch Tensor which is the underlying structure of a fastai.vision.Image. So the fastai Image wraps the pytorch tensor and you can initialize it using such, as I demonstrated.
If Image(t) does not work, you should make sure that you have indeed imported fastai.vision.Image (or from fastai.vision import *) and that you are not importing a PIL.Image to be accessible directly.
Meaning if you from PIL import Image or *, you will maybe have conflicts as both modules try to be accessible using the same Image(t) name. Try to only do import PIL and use PIL.Image everywhere that you want a PIL Image. Or use fastai.vision.Image to directly specify you want a fastai image.
About the transforms magic: You heard in the course about data augmentation I assume. A fastai.Image implements such apply_tfms function. This func applies the transformations of your data augmentation to the Image before using it.
Also, the open_image function is only used to load images from disk. You can always call doc(open_image) (or whatever other function) to get information about what it does and what kind of type the parameters have.
Dominik, thanks again for your help. I got a chance to circle back around to this and found this code to work:
t = torch.tensor(np.ascontiguousarray(np.flip(frame, 2)).transpose(2,0,1)).float()/255
img = Image(t) # fastai.vision.Image, not PIL.Image
p = learn.predict(img)
without the “.float()” I was getting an error: Expected torch.cuda.FloatTensor but got torch.cuda.ByteTensor
without the “/255” I was getting all black pixels (float expects range 0-1)
and with your “1 - torch.tensor” the image it returned was inverted
Now it is working: reading the video.mp4 file and predicting without writing the individual image.jpg files to disk. Unfortunately, it is still very slow making the predictions: 5 minute source @ 60 fps (~19k frames) is taking more than 23 minutes (13 frame predictions per second).
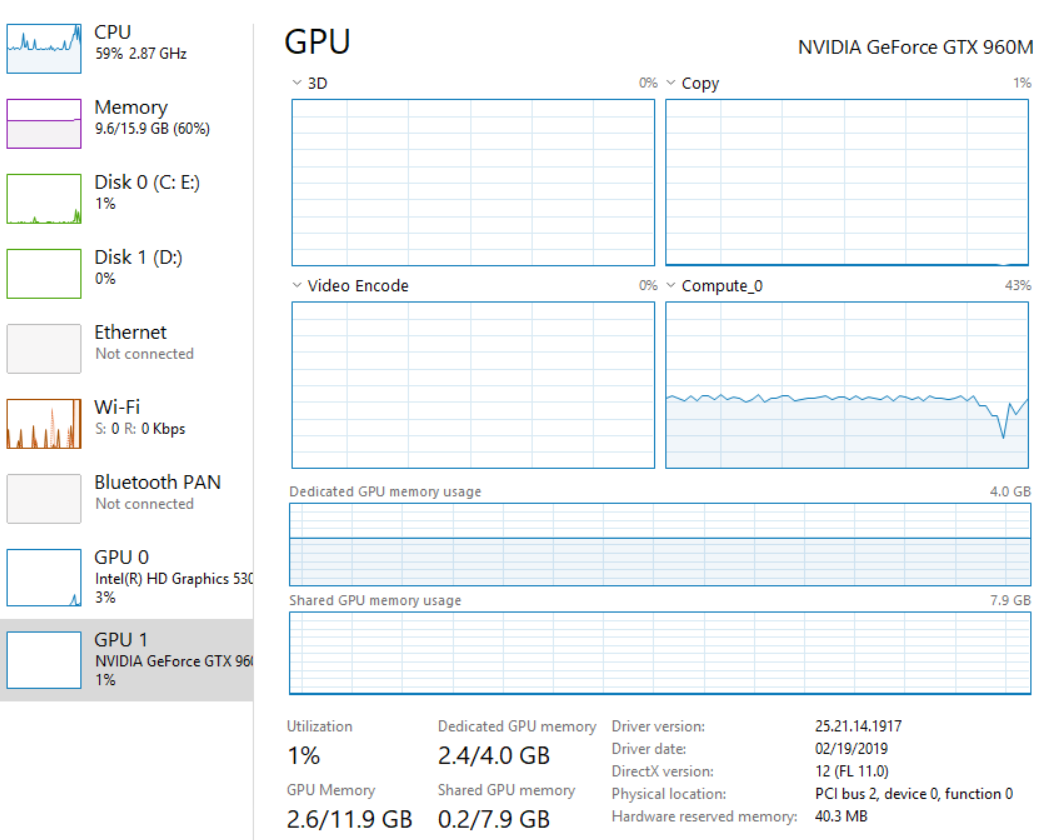
My CPU is only at 50% and my GPU is at 1% (only the GPU “Compute_0” shows usage at ~40%) and “img.device” returns “device(type=‘cpu’)”, so maybe I need to look elsewhere to speed up the prediction process…