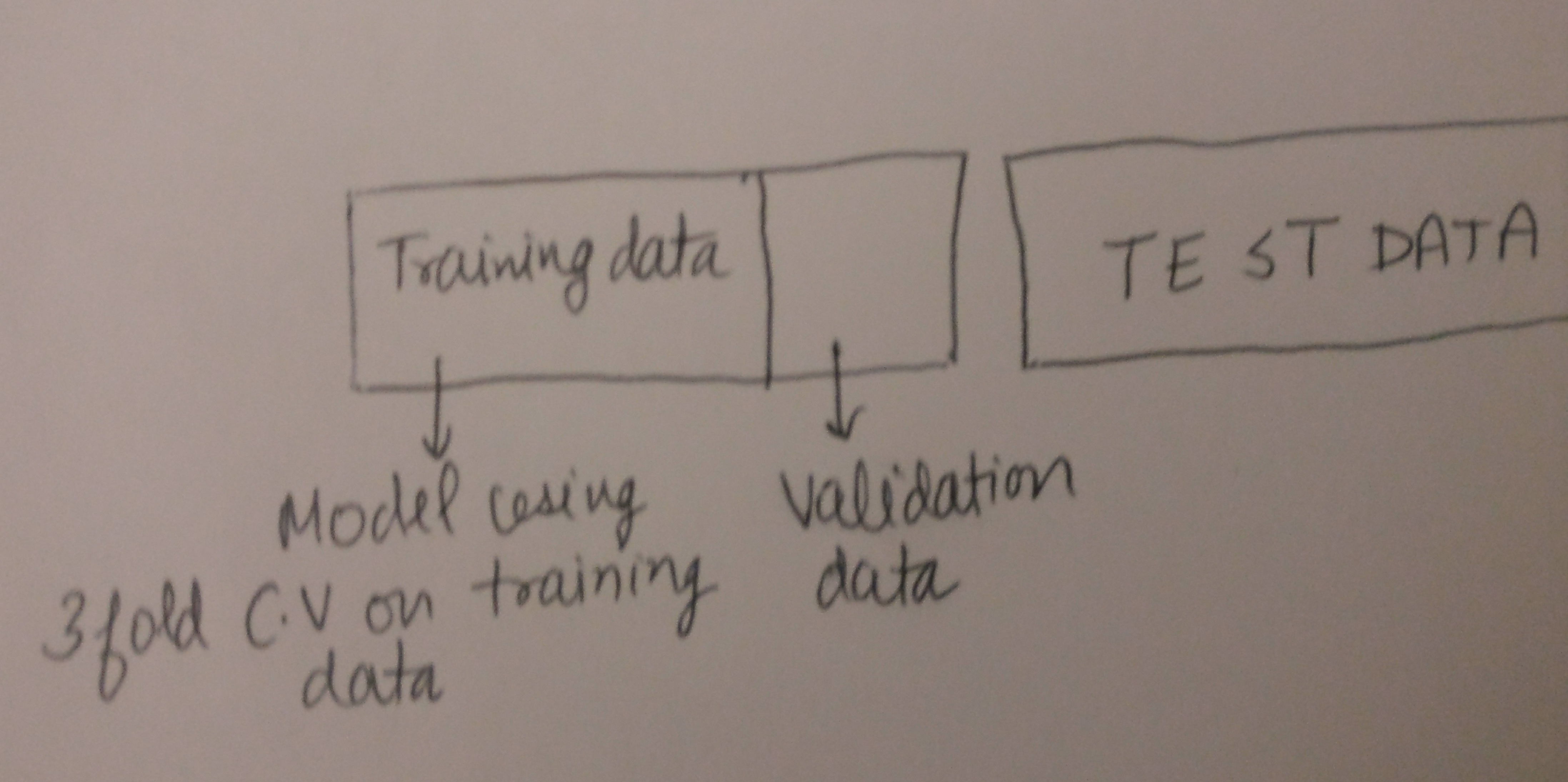
Possible reason for these 2 scenarios is that data being highly imbalanced, downsampling has been applied to training data (which goes to validation data also), but not in the test data which makes validation score and test score very different.
Which one should be chosen? Why in the 2nd case, validation score is very high (which points to good model) but test score is still low ? The cross validations score will make chose the 2nd model, but is it doing overfitting? Which one is better representative for predictions ?
Better validation is always what you care about. Unless you’re validation set isn’t set up properly, of course!
But in your case, validation results and test results aren’t aligned. That means your validation set isn’t a good indicator of your test set. So you need to try to create a better validation set.
In your case, it sounds like you’re using a random subset, or cross validation, for your validation. This probably isn’t what you want, if there’s any time dependence in your data (e.g. groceries, bulldozers).
Cross-validation is, in practice, not often useful, since most of the time a random sample doesn’t make for a good validation set.
Reason for random subset rather than sequential = rows of data are not in any sequence (like time in grocery). Although I will try taking a sequential sample also and will see how it changes.
The target variable is binary and there is a difference in distribution of target variable in validation data and test data. This is because of downsampling being done before making a model. But same downsampling can not be done on test data as it is hold out set and is taken out for final predictions.
So, is downsampling not right approach in this case? (Because it made validation set to be not a good representative of test set).
Ah OK! That means you need to ‘undo’ the downsampling when you calculate validation set predictions. E.g. if you’ve got 5x less of some class, you’ll underestimate the probability of that class, so you’ll need to multiply your probabilities from the model.
So I hope you don’t mind, I am going to jump in here with a related question.
Looking at your questions, Im realizing that I often have a hard time recognizing when I am overfitting. I understand the theoretical idea, but I guess I get lost in identifying it practically.
Looking back to when this was first identified (image below) and the example Prince gave above, could someone explain what is causing us to identify this as overfitting?
In the above snapshot, the 3rd score coming out from ‘print_score’ is m.score(x_train, y_train) , means how well our model predicts for training data. And the 4th score is m.score(x_valid, y_valid), i.e. same model being used to predict target on hold out validation data.
By looking at 3rd and 4th scores, we can see that our model predicts great for the data that it has seen for modeling (98.28% accuracy), but this accuracy (whatever score we choose) is reduced to 88.76% for the hold out data that it had not seen during model fitting.
This leads us to conclusion that our model might just be over fitting to the training data.
That is why it is written that although high-80’s score for validation data is not that bad, but model attained high 90’s for training set. So there might be scope of improvement.
OK. I will try, but correct me if you think I am wrong.
So one thing to notice in above case was that we had a ‘training set’ and a ‘validation set’. So we had done train-test split. Now, the bad score of validation as compared to training set could be because of 2 possible cases (as discussed in the snapshot)
We were overfitting because we might have used bad tuning parameters/ more features OR
Maybe the validation set is not correct representative of training set. (sampling not done right)
So, what if our total dataset size (rows) is not so big that we could split into train-validation split. Then we might not have validation set to check everytime whether we are overfitting or not.
Now, what OOB does in such case is, for every TREE that was there in FOREST, it calculates ‘score’ based on the data that model (tree model) had not seen. (indirectly making a validation set in itself). We know that if ‘bootstraping’ is TRUE, then each tree gets n observations WITH replacement. So there is no guarantee that tree will have all distinct rows to model. There are generally left out observations on which OOB score is calculated.
This can give us a good idea how good the model (from each TREE) is able to predict on observations that it doesn’t see.
That means you need to ‘undo’ the downsampling when you calculate validation set predictions. E.g. if you’ve got 5x less of some class, you’ll underestimate the probability of that class, so you’ll need to multiply your probabilities from the model.
Can you please expand on this? I tried under sampling as well but did not think about the consequences on the test set.
The idea is - since you changed the probabilities using under-sampling, you have to adjust the predictions to compensate for that. But if your scoring criteria is GINI or ROC-AUC, it won’t matter, you can skip this step. The reason is that these metrics are based on sequence (ranks) of predictions rather than actual prediction values.
So my understanding is that for under sampling you are throwing away information. Is there any detriment to over sampling? Also, anyone have experience with SMOTE or some similar method whereby new minority class data points are generated?