hi all, i am new to fastai and I experimented with Cats and Dogs dataset after watching Lesson 1.
I am using fastai version 1.0.52 . I have downloaded data from kaggle on colab and arranged data in “path” folder having folders “train’, “test” and"valid” with labelled folders in both “train” and “valid” folders(i.e. cats and dogs). The following is the code I have used
from fastai.vision import *
from fastai.metrics import error_rate
np.random.seed(0)
data = (ImageList.from_folder('path/train')
.split_by_rand_pct()
.label_from_folder()
.transform(get_transforms(),size=224)
.databunch(bs=64).normalize(imagenet_stats))
model=cnn_learner(data,models.resnet50,metrics=error_rate)
model.fit_one_cycle(5)
model.lr_find()
model.recorder.plot()
labelled_preds = [float(max(pred[0],pred[1])) for pred in log_preds_test[0]]
fnames = [f.name[:-4] for f in learn.data.test_ds.items]
fnames=list(map(int,fnames))
df = pd.DataFrame({'id':fnames, 'label':labelled_preds}, columns=['id', 'label'])
df=df.sort_values(by=['id'])
df.to_csv('path/submission.csv', index=False)
print(df.head())
made a few submissions in kaggle and got score of 3.015,3.7,4.755…which are terrible regarding the best scores to be 0.033-0.04.
Can anyone kindly show me any mistakes that I might have done?
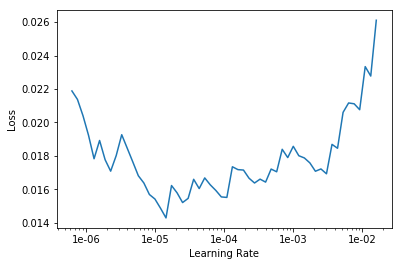
Which learning rate did you use for phase 1 learning? Can you show the plot of the learning rate scheduler?
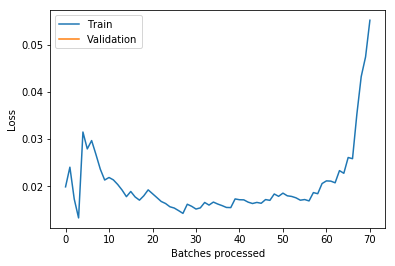
Also I recommend to add a callback to save the best model constrained on the metrics to safeguard against overfitting, which in your case seems to have happened.
Regarding learning rate, after performing model.lr_find() please execute model.recorder.plot() and show what it tells. Based on that you should choose a learning rate.
All this is also demonstrated in the video lessons of course 1.
I have already attached the result of model.recorder.plot() in my question , and that’s why I set learning rate as slice(1e-6,1e-5) after unfreezing the model. Still got bad results
Considering that this competition uses the cross entropy loss as the target metric, what you are seeing here is your model being very accurate, but also very confident about its wrong predictions. It is also likely that the validation set is not particularly similar to the test set, so that throws you off.
The submission file should contain the probabilities that the image is a dog: https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/overview/evaluation. But you are submitting labelled_preds = [float(max(pred[0],pred[1])) for pred in log_preds_test[0]] which is incorrect. You need to submit labelled_preds = log_preds_test[:, 0(or 1)].numpy() depending upon the index of the dog class. Also, verify the order of the predictions from the sample_submission_file in case you still get a bad score.
@rohit_gr you were absolutely correct, it was a terrible mistake on my part, got a score of 0.06033
thank you very much and thank you @miko for suggesting to use TTA