Notebooks are missing!!! I just ran a git pull. Root folder looks like this after re-starting:
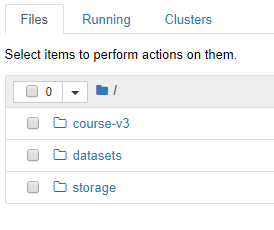
but looked like this before:
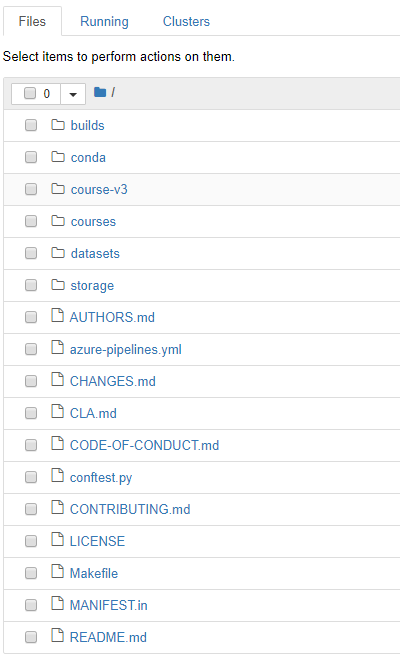
and the nbs folder is missing completely!
Please fix this ASAP!!!
Notebooks are missing!!! I just ran a git pull. Root folder looks like this after re-starting:
but looked like this before:
and the nbs folder is missing completely!
Please fix this ASAP!!!
I had the exact same issue more than once. Sometimes the whole nbs directory is missing, sometimes only dl1. I contacted support but it did not help much. Finally I opted to create a new notebook and start over (I had my own ipynbs in a repository so it was easy to move them back to the new nbs/dl1/). Now I am having another issue which is that even though I save my ipynb, when I stop the notebook and re-start it later, the version of my ipynb is not the most current. I give up with paperspace, I’ll try another service.
I agree; I’m planning on moving to GCP soon. I had no response to my post from Paperspace. I’m using Gradient and went back to the previous nb so I don’t think I lost much work this time, but it’s really upsetting to have the platform this unreliable.
No gpu’s available??!! Tried to restart a vm, had only a list of cpu’s, no gpu’s. Now tried again, has only GPU+, but I wanted to run with a faster gpu. What is going on???
this worked for me but I had ‘cd course-v3’ before git statsh, git pull as stated, at first i did git pull from home directory, thinking it would update everything, but it didn’t work until i cd’d to course-v3 directory.
@dillon any advice for installing the Anaconda Extensions for the Jupyter Notebook on a Paperspace instance (using the Fast.ai 1.0 / PyTorch 1.0 BETA container)? I followed the steps outlined here after finding this on the forum, and the install finishes successfully in the terminal, but it doesn’t seem to be working because I don’t have the nbextension option once I relaunch the notebook.
Thanks.
FYI we added support for GCP preemptible instances to our 1-click Jupyter Notebooks:
So, I had started the previous course on a Paperspace instance, but when I saw v3 announced I decided to re-start the course with the new version of the library. I’m following the Gradient set-up instructions.
When I try to open a terminal via the Notebook, the resulting terminal doesn’t have ‘normal’ terminal behavior. E.g., when I start typing a folder name and hit tab, it doesn’t autocomplete the folder – it gives me an actual tab space.
Is this typical? Is there any way to enable the behaviors I’m used to in my Mac terminal?
Also, with Gradient is there a way to transfer files between my machine and whatever I’ve got in the cloud? Say, I wanna run a model with my own data. How do I get the data into the Gradient environment to run on my own?
Or alternately, is there any way to set up the environment for v3 of the course in a VM instance so I can have all of the behaviors I’m used to? I couldn’t find instructions for that anywhere.
Also, what are people’s experiences with the “preemptible” sessions? Not that interruptions are regular and predictable like a train schedule, but about how often (besides the 24-hour maximum) do they happen?
Hi,
I am currently working on GPU+ on Paperspace. I have recently transitioned to v3, however I would like to retain the GPU+. I see for this course a separate repo was created course-v3/. Could I just clone this repo? Do I need to update any other libraries?
Thanks in advance!
Hi @dillon , I dediced to go through the Gradient approach using a P4000. However, I am getting an error
Error creating volume: Error response from daemon: create jsmksqrc7fmgp6: error while creating volume path ‘/var/lib/docker/volumes/jsmksqrc7fmgp6/_data’: mkdir /var/lib/docker/volumes/jsmksqrc7fmgp6: no space left on device.
It seems like the notebook is running, however cannot access it.
Hey I got the same error, deleted the notebook and did the setup again but didn’t work:
I’m a linux/jupyter notebook beginner who is completely lost on the process of installing software like google_images_download to get datasets together for level 1. I followed this thread…
Tips for building large image datasets, but wget doesn’t work in the jupyter terminal.
Thanks in advance for the help.
@adric This terminal behavior is expected/normal for Jupyter  The terminal in Jupyter Lab, the newest version of Jupyter, is a bit better but it’s still not nearly as functional as say the default terminal on a Mac/Linux system.
The terminal in Jupyter Lab, the newest version of Jupyter, is a bit better but it’s still not nearly as functional as say the default terminal on a Mac/Linux system.
Jupyter has an upload button and you can easily upload data to /storage, a persistent directory for storing data. For large datasets, you could either set up a VM and transfer files to /storage using SCP (or just use the VM itself). To clarify, both VMs and Gradient can access the /storage directory.
Hope that helps!
@crayoneater Great question. This article says “preemption rate varies between 5% and 15% per day…on a seven day average, occasionally spiking higher depending on time and zone”.
I definitely recommend checkpointing the model so if your session is interrupted, you can pick up where you left off/don’t lose your work.
@dkobran Thanks! I’d kinda wanna just set up the VM and run that. But it’s not clear how to get the VM setup for the new course. From what I can tell, the public template for fast.ai installs the v0.7 for the old course – I’m a noob, so not quite sure how to update the libraries and notebooks for the new course. Any pointers?
@adric Totally understand. We did set up the new template ourselves so let me see if I can gather some info from our team. Be right back 
@MadeUpMasters You can use wget in the Jupyter terminal – it’s just not available by default. Just run:
apt-get update
apt-get install wget
@Alican1 @Jeffrey Really sorry about this, we found a bug with the most recent Fast.ai container and it has been fixed. Happy to credit you for any lost time dealing with this.
I started an instance of a P4000 notebook and immediately stopped it. It has been in the process of “stopping” with a spinning circle for over an hour. What should I do? Am I being billed? Thank you.