I am getting following error:
bash: line 1: syntax error near unexpected token newline' bash: line 1:<!DOCTYPE HTML PUBLIC “-//IETF//DTD HTML 2.0//EN”>’
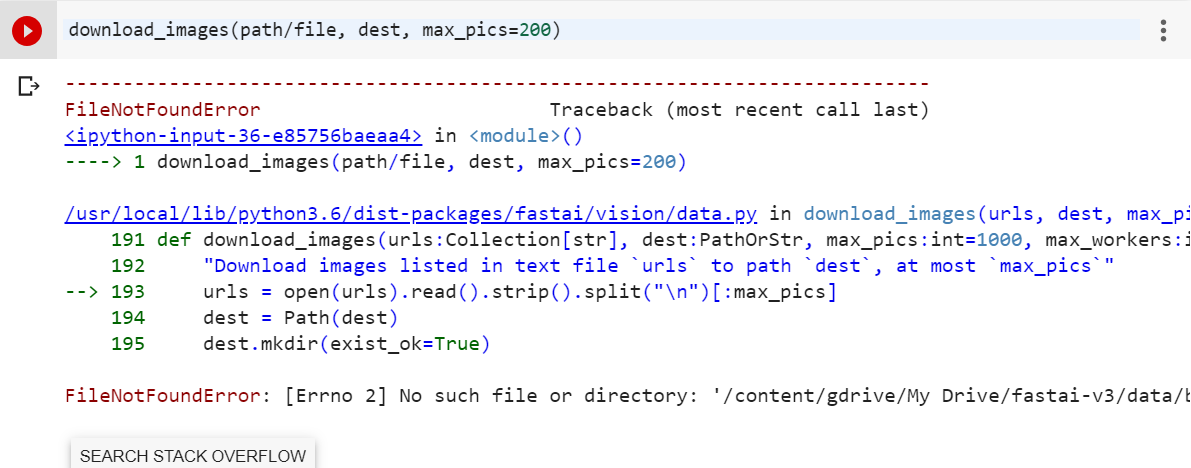
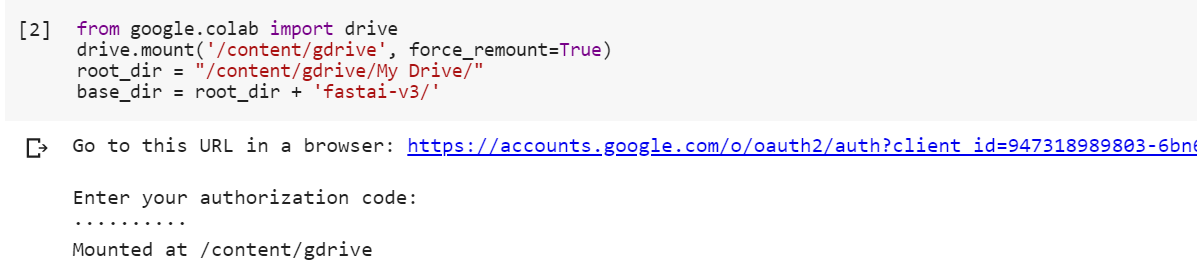
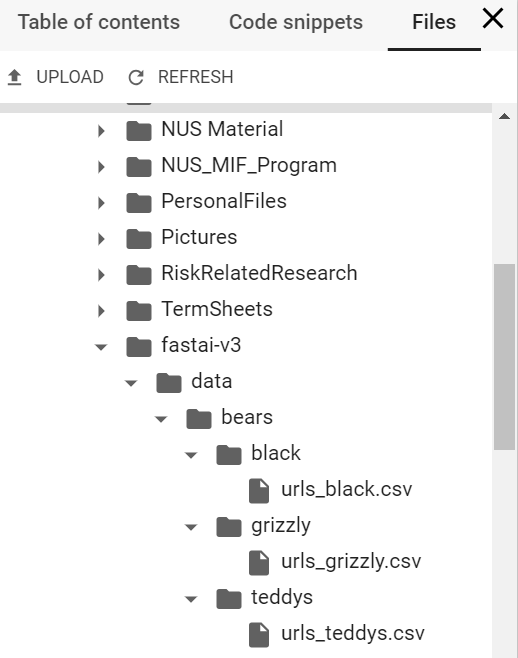
I get the same error. No such file or directory. As you can see, I have the used the code to set the directory to Mydrive/fast-ai as specified in the colab page (see the screen shots below).Not sure what is going wrong here!
I am not a professional programmer, so any help would be greatly appreciated!!
Hi guys, I am trying to work on Colab with a large datset (around 17GB) that I really want to use, it is a .jpg collection of paintings (you can find it here https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset). I have tried everything in order to load it to Colab, but nothing seemed to work fine. What would be your suggestion to work with these kind of datasets?
Did you define your folder? you can check your path/file and dest. I found that path/file need to change to path/folder/file in order to work on my problem.
I think that the best solution would actually be to create some GCP storage buckets and interact with them through the python API (https://cloud.google.com/storage/docs/json_api/v1/buckets). The advantage of this is that it should be much quicker than Google drive and easier to use through Python. The disadvantage is that it’s not free - though it’s very inexpensive and if you’re using GCP credits it is essentially free.
I need to spend some time figuring out the best approach here, but I think that ultimately creating a new load_from_gcp_bucket method on the relevant fastai itemlist would be the best approach. It would also be useful to set up something to persist models back to GCP buckets automatically.
thanks for the detailed answer! I will try your solution and let you know how it worked; GCP storage shouldn’t be that expensive considering we will not be training there. I am just baffled to understand how people train models with large datasets, is it normal practice here to train a model on a small subset of data and then apply it to the whole dataset?
I’m trying to train a language model on spanish wikipedia extract like this
data_lm = (TextList.from_folder(PATH)
#Inputs: all the text files in path
.filter_by_folder(include=['eswiki'])
#We may have other temp folders that contain text files so we only keep what's in train and test
.split_by_rand_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
However Collab is crashing after consuming all the 12Gb of RAM, is there a way to avoid this OOM?
I would first try using google drive (if you have storage for it) and if it doesn’t work, then use GCP storage buckets just to see if you can get it to work for free. Another alternative is to try to resize the images ahead of time, because your are probably going to anyway resize them to about 224x224
Try to reduce the bs(batch size)
Try with the range of bs values less than what you have used now and that should work fine
Also choosing GPU give you more RAM over choosing TPU on colab
Another reason would be having parallel notebooks running so the RAM is shared
Even if this doesn’t work out you can connect your local runtime(your own PC) and use it on colab instead of k80 which they give you
See the above screenshot. I did create the folder and uploaded the file (you can see that in the earlier screenshot). It just keeps throwing the same error. Are there any other libraries that we are supposed to import in this notebook? This is really driving me nuts. Appreciate your help!
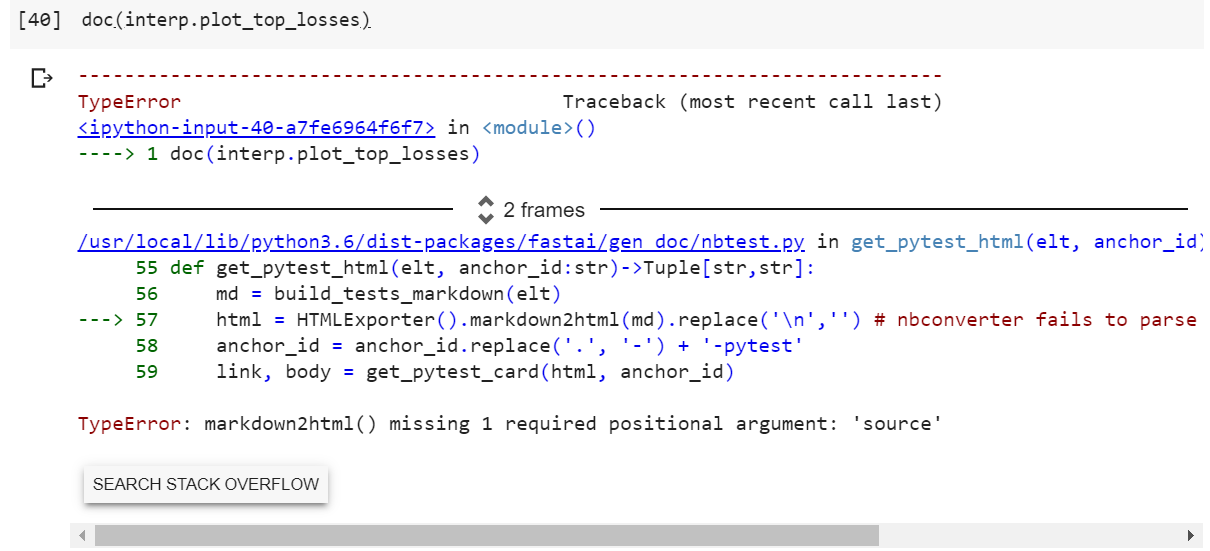
In notebook 2, image classification problem, the doc() method doesn’t work. help() works, but not doc. It throws the below error. Any ideas, what is happening here?
Just as an update. I have tried pretty much everything and the only way to train large datasets on Colab I could find was to run !cd data && gsutil -m cp -r gs://{yourbucketname}/ . on Colab to temporarily download my data in the Colab workspace. It is obviously pretty long and if Colab crashes you basically have to download the whole dataset all over again. Unluckily, I wasn’t able to mount gcs buckets as normal filesystems (as you would do with Drive), this would be extremely helpful.
If you guys happen to have other suggestion plase let me know
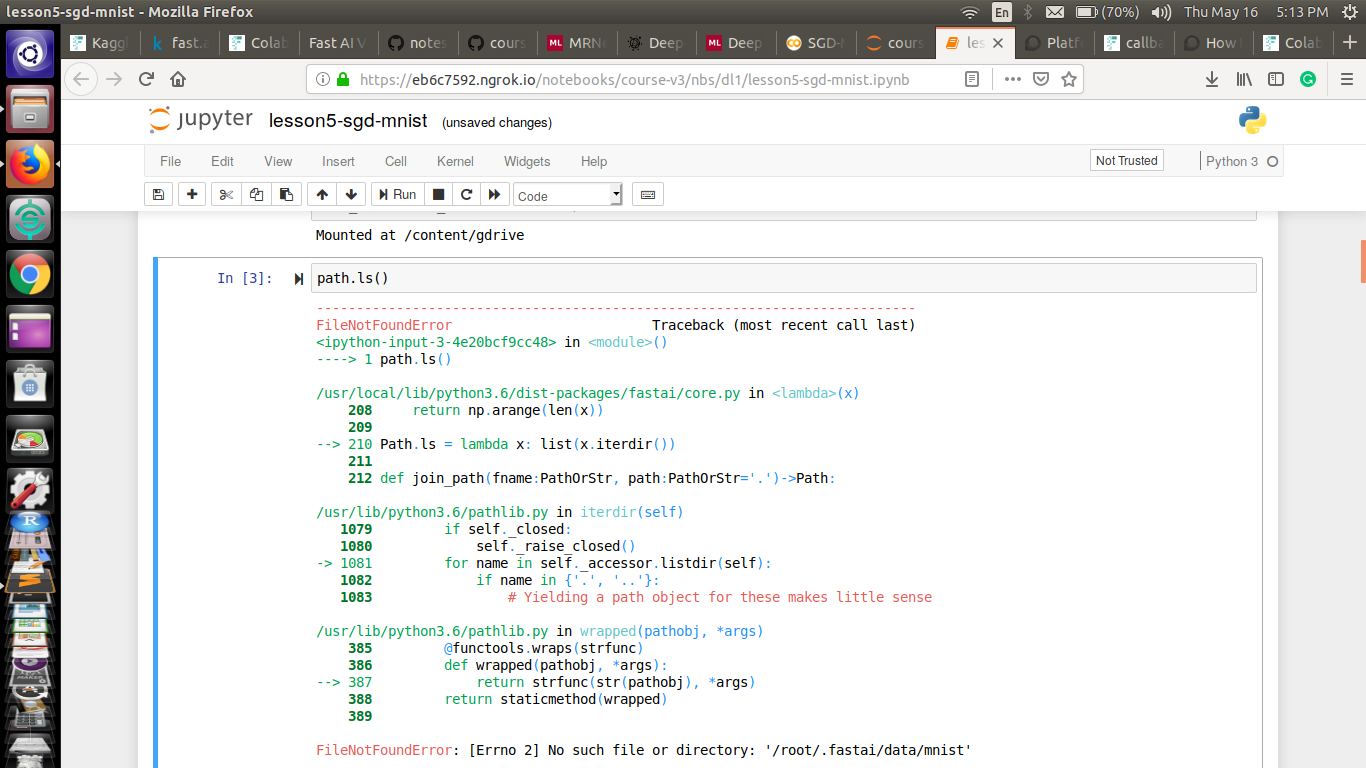
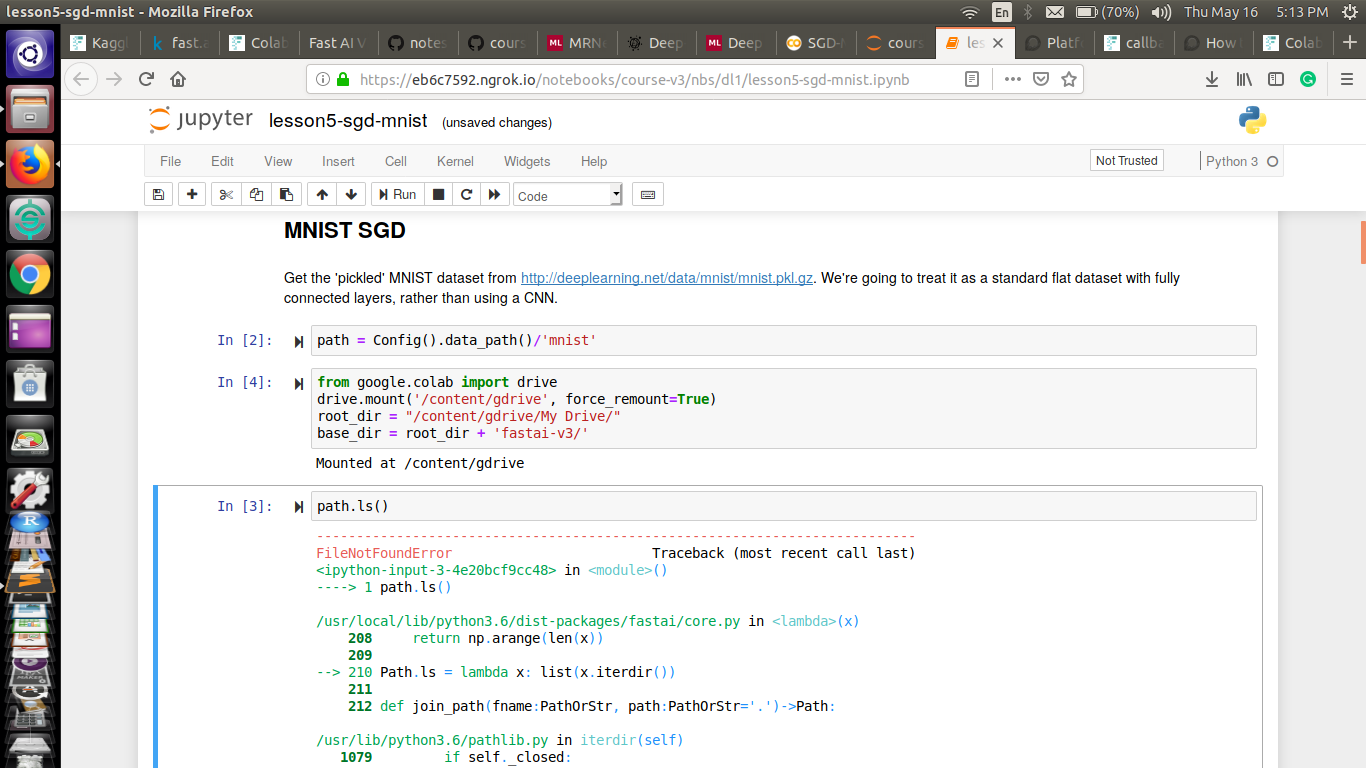
Hey guys, I have been using Kaggle for this course but I’ve decided to switch to Colab. I am doing the lesson 5 SGD-MNIST notebook, and I am getting this file not found error as shown below. It is a really naive doubt but I don’t know how to solve it.
I ran into the same problem recently and there is a fix for it here.
I haven’t tinkered anything and am still relying on placing ? (docstring) or ?? (source code) after or before the function I want more information for. Let me know if you try this fix and it works for you.