Problem - Colab session timing out after 12 hours model requires 20 hours what is the solution?
Hi everyone hope all is well!
In https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-imdb.ipynb the snippet below takes 1 hour 55 minutes to complete. (with GPU enabled)
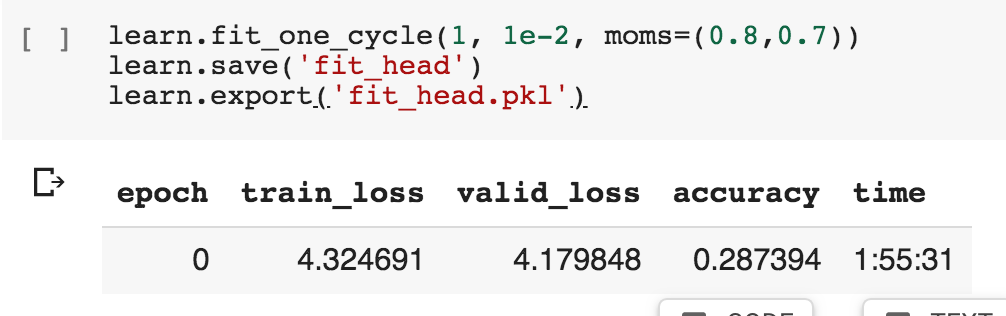
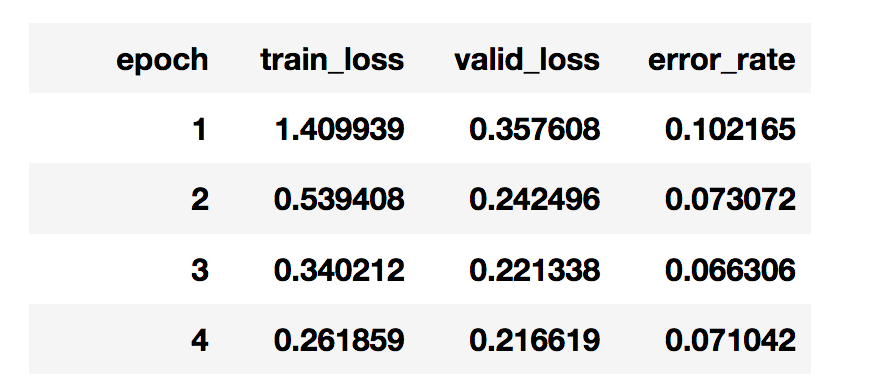
The snippet learn.fit_one_cycle(10, 1e-3, moms=(0.8,0.7)) below takes approximately 20 hours. Google Colab resource limit is set at 12 hours, which means the session is terminated before its finished. (frustrating
 )
)

Any Idea’s how to resolve this problem?
Reading the forum possible solutions could be:
- checkpoints
- callbacks
- run learn.fit_one_cycle(10, 1e-3, moms=(0.8,0.7)
saving and reloading after each epoch. I haven’t got my code to work so far.
Any solutions, tips or ideas greatly appreciated.
mrfabulous1 